In Kapitel 3.1 (Übernatürliche Zahlen) haben wir die
sogenannten übernatürlichen Zahlen kennengelernt.
Sie tauchen auf, wenn wir \( \neg G \) als neues Axiom zu den Peano-Axiomen hinzufügen.
Die Objekte, über die dieses erweiterte Axiomensystem Aussagen macht, umfassen dann
neben den natürlichen Zahlen auch übernatürlichen Zahlen, die
gewissermaßen größer als alle natürlichen Zahlen sind.
Solche übernatürlichen Zahlen sind keine Zahlen im üblichen Sinn mehr,
sondern sie sind neuartige mathematische Objekte, über deren Bedeutung man erst einmal nachdenken muss.
Ähnlich war es auch mit der imaginären Einheit \( i \) gewesen, deren Quadrat gleich
\( -1 \) ist. Auch \( i \) ist keine Zahl im gewohnten Sinn,
kann aber durchaus geometrisch interpretiert werden (siehe Kapitel 3.1).
Wir hatten in Kapitel 3.1 bereits gesehen, wie man
ein konkretes mathematisches Modell für übernatürliche Zahlen im Rahmen der Mengenlehre
konstruieren kann (Details zum Modellbegriff siehe Kapitel 4.4).
Außerdem hatten wir angedeutet, dass man auf diese Weise eine sogenannte Nichtstandard-Analysis
aufbauen kann, in der die bei Physikern so beliebten infinitesimalen Größen sauber
definiert sind. Wie das genau geht, wollen wir uns in diesem Kapitel einmal ansehen.
Die Nützlichkeit unendlicher Größen und ihre Verbannung aus der Mathematik
Die Analysis – auch Infinitesimalrechnung genannt – befasst sich in gewissem Sinn mit
unendlich kleinen und unendlich großen Objekten.
Solche Konzepte benötigt man in der Praxis häufig.
Hier zwei Beispiele:
Kreis:
Einen Kreis kann man sich angenähert als ein regelmäßiges \(n\)-Eck vorstellen,
bei dem die Zahl der Ecken immer größer wird.
Die Kreisfläche besteht dann aus \(n\) schmalen Tortenstücken (dünnen Dreicken).
Ein \(n\)-Eck mit einer Millionen
Ecken sieht praktisch schon genauso aus wie ein Kreis. Man kann einen Kreis
als Unendlich-Eck auffassen, zusammengesetzt aus unendlich vielen unendlich dünnen Tortenstücken.
Mit solchen Ideen kann man die Kreiszahl \( \pi \) berechnen.
Je mehr Ecken ein regelmäßiges \(n\)-Eck hat, umso kreisähnlicher wird es.
Momentangeschwindigkeit:
Die Momentangeschwindigkeit ist die Geschwindigkeit, die ein Objekt
zu einem bestimmten Zeitpunkt besitzt. Bei einem beschleunigten Objekt
ändert sich die Momentangeschwindigkeit ständig.
Um sie zu messen, muss man ermitteln, wieviel Zeit das Objekt braucht, um eine sehr kleine Wegstrecke zurückzulegen.
Die Wegstrecke muss so klein sein, dass sich die Geschwindigkeit entlang dieser Strecke
kaum ändert. Will man es ganz genau wissen, so müsste die Wegstrecke
– nennen wir sie \(dx\) – unendlich klein (infinitesimal) sein.
Entsprechend wäre auch die Zeitspanne –
nennen wir sie \(dt\) – zur Überwindung dieser Wegstrecke
unendlich klein. Die Geschwindigkeit \(v\) wäre dann der Quotient aus der unendlich kleinen
Wegstrecke, dividiert durch die unendlich kleine Zeitspanne:
\[ v = \frac{dx}{dt} \]
Weg-Zeit-Diagramm für ein beschleunigtes Objekt.
Die Momentangeschwindigkeit zu einem bestimmten Zeitpunkt ist durch die Steigung der Kurve in diesem Punkt
gegeben. Man kann sich vorstellen, dass man dazu
die Kurve bei diesem Punkt unendlich stark vergrößert (Lupe), so dass die Kurve dort
wie eine Gerade aussieht. Nun kann man die Steigung der Geraden per Steigungsdreieck ermitteln:
\( v = \frac{dx}{dt} \) . Nimmt man die Vergrößerung zurück, so werden
\(dx\) und \(dt\) unendlich klein.
Bereits in der Antike gab es erste Versuche, mit solchen unendlich kleinen
oder unendlich großen Objekten vernünftig umzugehen.
Schon Archimedes verwendete das regelmäßige \(n\)-Eck,
um den Kreis näher zu untersuchen (siehe oben).
Er konnte so begründen, dass die Fläche \(A\) eines Kreises gleich
dem halben Produkt aus Radius und Umfang sein muss: \( A = \frac{1}{2} r U \).
Aber es gab ein Problem, das wir auch von anderen neu eingeführten mathematischen Konzepten
her kennen: Um bestimmte Probleme zu lösen, entwickelt man zunächst
eher intuitiv neue mathematische
Konzepte, ohne diese sofort streng formal begründen zu können.
Diese neuen Konzepte verwendet man dann eher nach Gefühl und mit einem gewissen Unbehagen.
So war es mit den reellen Zahlen, die in der Antike noch unbekannt waren,
und so war es mit der imaginären Einheit \( i \) , die man nur mit großem
Unbehagen benutzte, bis Gauß ihr eine geometrische
Interpretation gab. Selbst der Mengenlehre mit ihren nicht-konstruktiven Methoden
und mathematischen Monstern erging es nicht anders.
So wundert es nicht, dass auch die intuitive Verwendung
unendlich kleiner Größen wie \(dx\) und \(dt\) im zweiten Beispiel oben
Anlass zu Kritik gab. Sie erschienen zwar irgendwie nützlich,
doch was genau sind diese unendlich kleinen Größen?
Sie sind weder endliche Größen, noch sind sie gleich Null.
Sie sind wie die Geister dahingegangener Größen, die sich im Nichts verflüchtigen,
ohne jemals vollkommen zu verschwinden.
Um das Jahr 1872 herum kam die Rettung durch die Arbeiten von
Dedekind, Cantor, Cauchy und Weierstrass: der sogenannte \( \epsilon - \delta \) - Formalismus.
Genau so lernt man heute in der Schule (Oberstufe) und Universität Analysis!
Schauen wir uns am Beispiel der Stetigkeit an, wie das Problem gelöst wurde:
In der Analysis bezeichnet man anschaulich eine reelle Funktion \(f(x)\) als stetig,
wenn sie keine Sprünge macht. Man kann den Graphen einer stetigen Funktion
mit einer Linie ohne Unterbrechungen durchzeichnen.
Bei einer stetigen Funktion soll sich \(f(x)\) nur ein wenig verändern, wenn
man \(x\) nur ein wenig ändert. Statt ein wenig müsste man genau genommen
wieder sagen: unendlich wenig. Und schon sind sie wieder da: die unendlich kleinen Objekte.
Cauchy und andere präzisierten diese anschauliche Vorstellung nun auf die folgende geniale Weise:
Wir schauen uns einen bestimmten Punkt \(x_0\) an und fragen uns, ob \(f(x)\) in diesem Punkt stetig
ist, sich dort also nicht sprunghaft ändert. Es ist nun wie bei einem Spiel:
Du gibst mir irgendeine reelle positive Zahl \( \epsilon \) vor
– sie darf auch sehr klein sein, aber
sie bleibt eine endliche positive reelle Zahl.
Diese Zahl \( \epsilon \) soll nun die maximale Änderung sein, die wir für \(f(x)\) zulassen wollen,
wenn wir uns mit \(x\) vom Ausgangspunkt \(x_0\) entfernen.
Und nun kommt der entscheidende Punkt: Ich sichere Dir zu, dass \(f(x)\) tatsächlich um
maximal den Wert \( \epsilon \) von \(f(x_0)\) abweicht, wenn du Dich nur nicht zu weit
von \(x_0\) wegbewegst. Ich gebe Dir sogar die reelle positive Zahl \( \delta \) mit, die Dir angibt,
wie weit Du maximal von \(x_0\) weggehen darfst.
Egal wie klein Du mir die maximale \(f(x)\)-Änderung \( \epsilon \) auch vorgibst,
ich kann Dir jedes mal ein entsprechendes \( \delta \) zurückgeben, um das Du Dich
von \(x_0\) entfernen darfst, ohne dass die \(f(x)\)-Änderung dabei den
vorgegebenen Wert von \( \epsilon \) überschreitet.
Die Kurzform dieser Idee lautet:
Stetigkeit:
\(f(x)\) ist im Punkt \(x_0\) stetig genau dann, wenn es zu jedem (noch so kleinen) reellen
positiven \( \epsilon \)
ein reelles positives \( \delta \) gibt,
so dass aus \( |x - x_0| < \delta \) folgt,
dass \( |f(x) - f(x_0)| < \epsilon \) ist.
Kurzschreibweise:
\[
\forall \epsilon > 0 : \, \exists \delta > 0 : \, \forall x \in \mathbb{R} :
\] \[
|x - x_0| < \delta \Rightarrow |f(x) - f(x_0)| < \epsilon
\]
Die Funktion \(f(x)\) in diesem Bild hat bei \(x_0\) (rote Linie) einen Sprung,
ist also dort nicht stetig. Wenn man hier ein \( \epsilon \) wählt, das kleiner als die Sprunghöhe
ist, dann gibt es hier im Allgemeinen kein dazu passendes \( \delta \), so dass
aus \( |x - x_0| < \delta \) mit Sicherheit folgt,
dass \( |f(x) - f(x_0)| < \epsilon \) ist. Egal wie wenig man sich bei \(x_0\) nach rechts bewegt,
so springt \(f(x)\) dennoch immer um mindestens die Sprunghöhe.
Wenn man diese Vorgehensweise zum ersten Mal sieht, ist man etwas verwirrt.
Sie erscheint irgendwie hinten herum zu sein.
Aber wenn man sie sich eine Zeit lang genauer ansieht, so stellt man fest, dass sie genau das
tut, was man wollte: Eine Funktion, die sich so verhält, ändert sich nicht sprunghaft!
Dabei ist es gelungen, die anschauliche Idee, die noch mit unendlich kleinen Objekten
hantierte, vollkommen ohne solche schwer fassbaren Objekte zu formulieren.
\( \epsilon \) und \( \delta \) sind reelle endliche Zahlen. Der Trick funktioniert, weil man
fordert, dass man jedes beliebige positive \( \epsilon \) vorgeben darf, auch ein sehr kleines.
Die Aussage muss für alle positiven \( \epsilon \) gelten.
Anschaulich stellt man sich natürlich vor, dass man immer kleinere \( \epsilon \) vorgibt,
und dass man dann auch immer kleinere \( \delta \) zurückgeben muss.
Aber diesen Vorgang immer kleiner werdender Zahlen muss man nicht formell ausschreiben.
Er ist indirekt in der Formulierung bereits enthalten.
Die Mathematiker waren erleichtert. Endlich war es gelungen, diese merkwürdigen
unendlich kleinen Objekte aus der Mathematik zu verbannen und die damit
verbundenen Ideen sauber und einwandfrei zu formulieren.
Aber die neue Vorgehensweise mit \( \epsilon \) und \( \delta \) hatte ihren Preis:
Irgendwie war sie etwas sperrig, unhandlich und unanschaulich.
Daher verwundert es nicht, dass viele Mathematiker und besonders viele Physiker
die anschaulichere Vorgehensweise mit den unendlich kleinen Größen beibehielten.
Es war einfach zu praktisch, beispielsweise die Kettenregel
in der Kurzform
\[ \frac{dy}{dt} = \frac{dy}{dx} \, \frac{dx}{dt} \]
zu schreiben und sich dabei vorzustellen, dass man das unendlich kleine \( dx \)
auf der rechten Seite nur wegzukürzen braucht, um die linke Seite zu erhalten.
Für diese etwas laxe Vorgehensweise mit den in Ungnade gefallenen unendlich kleinen Größen
wurde man dann von den mathematischen Puristen gerügt. Nur der
\( \epsilon - \delta \)- Formalismus besaß schließlich eine gesicherte mathematische
Grundlage.
Doch das hat sich seit dem Jahr 1966 geändert.
Abraham Robinson veröffentlichte sein Werk über Nichtstandard-Analysis
und wies nach, dass es sehr wohl möglich ist, ein solides mathematisches Fundament
für den Umgang mit unendlich kleinen und unendlich großen Zahlen zu schaffen.
Dies wird uns nach dem, was wir in Kapitel 3.1 (Übernatürliche Zahlen)
bereits erfahren haben, nicht mehr sonderlich überaschen. Schauen wir uns also die Idee genauer an,
wie man die nützlichen infinitesimalen Größen
\( dx \) und \( dt \) wiederbeleben kann:
Unendlich lange Folgen reeller Zahlen
Es gibt verschiedene Möglichkeiten, die Nichtstandard-Analysis anzugehen.
Ich werde hier den Weg verfolgen, der mir selbst am besten gefallen hat und der
nicht alleine auf einer abstrakten Formulierung basiert, sondern in dem
ein konkretes Modell erstellt wird. Mit diesem Modell vor Augen ist es dann leichter,
auch die abstrakte Vorgehensweise zu verstehen.
Was ein Modell ist, haben wir in Kapitel 4.4 bereits gesehen.
So kann man beispielsweise innerhalb der Mengenlehre ein Modell der
natürlichen Zahlen erstellen. Das bedeutet, dass man Mengen konstruieren kann, die
sich wie natürliche Zahlen verhalten (siehe Kapitel 4.2).
Auch reelle Zahlen und die gesamte Standard-Analysis kann man in der Sprache der Mengenlehre
formulieren.
Kann man auch für unendlich große und unendlich kleine Objekte eine Darstellung
durch Mengen finden, die sich so verhalten, wie wir das von diesen Objekten erwarten?
Aus Kapitel 3.1 (Übernatürliche Zahlen) wissen wir bereits, das das geht:
Man benutzt unendliche reelle Zahlenfolgen.
Diese Idee ist gar nicht so ungewöhnlich, wie sie zunächst aussieht.
Wenn man von den rationalen Zahlen (Brüchen) ausgeht, werden die reellen Zahlen
im Grunde ganz analog konstruiert: durch konvergierende Zahlenfolgen (sogenannte
Cauchyfolgen).
Die Dezimalschreibweise einer reellen Zahl ist genau so eine Zahlenfolge.
Die Kreiszahl \( \pi \) wird beispielsweise eindeutig durch die unendliche
rationale Zahlenfolge \( (3 ; \, 3,1 ; \, 3,14 ; \, 3,141 ; \, 3,1415 ; \, .... ) \) charakterisiert.
Ein anderes Beispiel ist die Folge \(f(n)\) mit \(f(1) = 1\) und
\[
f(n+1) = \frac{f(n)}{2} + \frac{1}{f(n)}
\]
deren erste Folgenglieder so aussehen:
\begin{align}
f(1) &= 1 \\
f(2) &= \frac{1}{2} + 1 = \frac{3}{2} = 1,5 \\
f(3) &= \frac{3}{4} + \frac{2}{3} = \frac{17}{12} = 1,41666 ... \\
f(4) &= \frac{17}{24} + \frac{12}{17} = \frac{577}{408} = 1,414215686 ...
\end{align}
Diese Folge, die nur aus rationalen Zahlen (Brüchen) besteht, konvergiert
gegen die nicht-rationale Zahl \( \sqrt{2} = 1,414213562 ... \) .
Man kann auch sagen, die obige Cauchyfolge definiert die Zahl \( \sqrt{2} \).
Dabei muss man allerdings berücksichtigen, dass auch andere Folgen aus rationalen Zahlen
gegen \( \sqrt{2} \) konvergieren können.
Man sagt daher, dass alle diese Folgen zusammen erst die Zahl \( \sqrt{2} \) definieren.
Zwei Cauchyfolgen, deren Folgemitglieder unendlich nahe zusammenrücken, definieren also
dieselbe reelle Zahl. Mathematisch sagt man, dass die nicht-rationalen (reellen) Zahlen
durch die entsprechenden Äquivalenzklassen von solchen gleichwertigen
Cauchyfolgen definiert werden (siehe z.B.
Wikipedia: Vollständiger Raum).
Diese Notwendigkeit, bei der Definition der neuen Objekte Äquivalenzklassen zu bilden,
wird uns unten wieder begegnen. Ein anderes Beispiel für diese Notwendigkeit ist
die Definition der rationalen Zahlen (Brüche), ausgehend von den ganzen Zahlen.
So legen die beiden Brüche \( \frac{2}{3} \) und \( \frac{4}{6} \) dieselbe rationale Zahl fest.
Vergessen wir nun im Folgenden die Cauchyfolgen wieder und denken uns reelle Zahlen einfach
als fertig konstruierte Objekte. Dann können wir unendliche Zahlenfolgen
aus reellen Zahlen dazu verwenden, um unendlich kleine und unendlich große
Objekte zu modellieren.
Beruhigend ist:
Unendliche Zahlenfolgen lassen sich als unendliche Mengen
darstellen (siehe z.B. geordnete Paare in Kapitel 4.2; das Prinzip ist analog
für unendliche Zahlenfolgen – die natürlichen Zahlen sind ein Beispiel dafür).
Insofern bewegen wir uns auf relativ sicherem mathematischen Boden: der Mengenlehre
(siehe Kapitel 4.1 und 4.2).
Hier kommt uns wieder einmal zu Gute, dass die Mengenlehre direkt mit unendlichen Objekten umgehen kann.
Wir wollen aber im Folgenden die sperrige Mengenschreibweise nicht verwenden, sondern eine Zahlenfolge
einfach wie oben und wie in Kapitel 3.1 notieren.
So schreiben wir für die unendliche Folge der Quadratzahlen beispielsweise
\[
(1, \, 4, \, 9, \, 16, \, 25, \, 36, \, ... )
\]
Gehen wir analog zu Kapitel 3.1 vor:
Zunächst einmal sorgen wir dafür, dass uns bei den unendlichen Zahlenfolgen die reellen Zahlen erhalten bleiben.
Wir stellen sie einfach durch konstante Zahlenfolgen dar.
So schreiben wir beispielsweise für die Kreiszahl \( pi \)
einfach die konstante Zahlenfolge
\[
\pi := (\pi , \, \pi , \, \pi , \, ... )
\]
Nun kommen wir zu den interessanteren Zahlenfolgen, beispielsweise zu der Zahlenfolge
\[
( 1 , \, \frac{1}{2} , \, \frac{1}{3} , \, \frac{1}{4} , \, ... )
\]
So eine Zahlenfolge könnte geeignet sein, ein unendlich kleines Objekt darzustellen.
Aber auch andere unendliche Zahlenfolgen wollen wir zulassen und sehen, wohin das führt.
Wir betrachten also im Folgenden die Menge aller unendlichen reellen Zahlenfolgen
und bezeichnen sie mit \( \mathbb{R}^\mathbb{N} \)
(das hochgestellte \( \mathbb{N} \)
steht für die Menge der natürlichen Zahlen, mit denen wir die einzelnen
Folgenmitglieder durchnummerieren können).
Da wir die konstanten Folgen mit den reellen Zahlen identifizieren,
sind die reellen Zahlen eine Untermenge von \( \mathbb{R}^\mathbb{N} \).
Natürlich wollen wir die gewohnten Grundrechenarten durchführen können.
Wir wollen ja weiterhin reelle Zahlen addieren, subtrahiern, dividieren und
multiplizieren können. Darüber hinaus wollen wir die Grundrechenarten aber auch mit den neuen
unendlich kleinen und großen Objekten durchführen können.
Unsere Hoffnung ist es ja, beispielsweise die Kettenregel
direkt als
\( \frac{dy}{dt} = \frac{dy}{dx} \, \frac{dx}{dt} \)
schreiben zu können.
Versuchen wir es mit der einfachsten Möglichkeit:
Zwei unendlich lange Folgen werden addiert, indem man die einzelnen Folgenglieder addiert, z.B. so:
\[
(1, \, 2, \, 3, \, ... ) + (2, \, 4, \, 6, \, ... ) =
\] \[
= (1+2, \; 2+4, \; 3+6, \; ... ) = \] \[
= (3, \, 6, \, 9, \, ... )
\]
Analog gehen wir auch bei der Subtraktion, Multiplikation und Division vor, beispielsweise so:
\[
\frac{(1, \, 2, \, 3, \, ... )}{(2, \, 4, \, 6, \, ... )} = \]
\[ =
\left( \frac{1}{2} , \, \frac{2}{4}, \, \frac{3}{6} , \, ... \right) = \]
\[ =
\left( \frac{1}{2} , \, \frac{1}{2}, \, \frac{1}{2} , \, ... \right) = \]
\[
= \frac{1}{2}
\]
Auf diese Weise können wir alle gewohnten Rechenregeln auf das Rechnen mit Folgen übertragen
und verlieren auch nicht das Rechnen mit den reellen Zahlen, die ja jetzt durch konstante Folgen
dargestellt werden. Wir kennen das bereits aus Kapitel 3.1.
Das zweite obige Beispiel ist interessant! Das Ergebnis ist eine konstante Folge,
die der reellen Zahl \( \frac{1}{2} \) entspricht.
Sie entsteht durch Division zweier anwachsender Folgen, wobei die Folgenmitglieder im Nenner
doppelt so groß sind wie die Folgenmitglieder im Zähler.
Man kann sich vorstellen, dass wir so
die Division zweier unendlich großer Größen in den Griff bekommen können, wobei die zweite Größe
gewissermaßen doppelt so groß wie die erste ist. Das könnte dann die übliche
Grenzwertschreibweise
\[
\lim_{n \rightarrow \infty} \, \frac{n}{2n} = \frac{1}{2}
\]
ersetzen, die über den \( \epsilon - \delta \) - Formalismus definiert ist.
Vergleich von Zahlenfolgen über dominante Indexmengen
Die Menge \( \mathbb{R}^\mathbb{N} \) der unendlichen reellen Zahlenfolgen
ist noch nicht genau die Objektmenge, die wir anstreben.
Für die gewünschte Interpretation der Folgen wird es wichtig werden,
welche Folgen wir als gleichwertig (also als gleich) ansehen wollen.
Wir erinnern uns: es geht um die angekündigten Äquivalenzklassen.
Damit zusammenhängend werden wir dann auch klären, welche Folge bei zwei
ungleichen Folgen die größere ist.
Genau dies ist der komplizierte Punkt bei der ganzen Angelegenheit.
Wir wollen ja keine Zahlenfolgen ausschließen, auch nicht so merkwürdige Folgen
wie \( (1, 0, 1, 0, 1, 0, ... ) \) . Ist diese Folge größer, kleiner
oder gleich der Folge \( (0, 1, 0, 1, 0, 1, ... ) \) ?
Und was ist mit den beiden Folgen \( (0, 1, 2, 3, 4, ... ) \) und \( (-1, 1, 3, 5, 7, ... ) \) ?
Gerne würden wir sagen, dass die zweite Folge größer ist, da alle ihre Folgenglieder außer
den ersten beiden größer sind.
Es macht offenbar keinen Sinn, zu fordern, dass alle Folgenglieder einer Folge \(a\)
größer (bzw. kleiner oder gleich) denen einer anderen Folge \(b\) sein müssen,
damit \(a\) größer (bzw. kleiner oder gleich) \(b\) ist.
Bei den meisten Folgen hätten wir dann
nämlich keine Entscheidung über ihren Größenvergleich.
Bei der Konstruktion reeller Zahlen durch Cauchyfolgen rationaler Zahlen ist es ähnlich!
Dort müssen zwei gleichwertige
Cauchyfolgen sogar überhaupt nicht an irgendwelchen Positionen gleich sein,
sondern sie müssen nur gegen dieselbe reelle Zahl konvergieren.
Das hat zur Folge, dass die beiden Cauchyfolgen
\begin{align}
a &= ( \frac{1}{2}, \, \frac{1}{4}, \, \frac{1}{8}, \, \frac{1}{16}, \, ... ) \\
& \\
b &= ( \frac{1}{3}, \, \frac{1}{9}, \, \frac{1}{27}, \, \frac{1}{81}, \, ... )
\end{align}
dort dieselbe reelle Zahl darstellen, nämlich Null.
Das soll jetzt aber anders werden: In unserem Modell soll jetzt nur die
konstante Folge \( (0, 0, 0, ... ) \)
die reelle Zahl Null darstellen, während die beiden Folgen oben
ein unendlich kleines Objekt wie \(dx\) darstellen sollen.
Daher müssen wir jetzt anders als bei den Cauchyfolgen vorgehen.
Letztlich bestimmt gerade die Art und Weise, wie wir die Größenverhältnisse und die Gleichheit
von Zahlenfolgen definieren, was für mathematische Objekte wir mit ihnen modellieren.
Daher wird unser intuitives Verständnis von unendlich kleinen und unendlich großen Objekten
dabei einfließen müssen – mal sehen, wo und wie.
Wenn wir zwei Zahlenfolgen \(a = (a_1, a_2, ...) \) und \(b = (b_1, b_2, ...)\)
miteinander vergleichen, dann soll es in unserer
Definiton eine Rolle spielen, wie sich die Mehrheit der Folgenglieder zueinander verhält.
Was Mehrheit hier bedeuten soll, müssen wir aber noch genauer festlegen.
Die Positionen in den beiden Zahlenfolgen können wir dazu in drei Gruppen aufteilen:
Die \(a\)-größer-Indexmenge, die alle Positionen (Indices \(i\)) umfasst,
bei denen bei den Folgengliedern \( a_i > b_i \)
ist, analog die \(b\)-größer-Indexmenge
sowie die Gleich-Indexmenge, die alle identischen
Positionen umfasst. Um eindeutig festzulegen, ob nun \(a\) größer, kleiner oder gleich \(b\) sein soll,
müssen wir uns entscheiden, welche der drei Indexmengen die Mehrheit repräsentiert und damit
den Ausschlag gibt, also gleichsam die dominante Indexmenge ist.
Das kann für jeden Folgenvergleich eine andere Indexmenge sein, denn die drei Indexmengen hängen
ja von den Folgen ab, die wir vergleichen.
Die drei Indexmengen für zwei Folgen \(a\) und \(b\).
Schauen wir uns nochmal die beiden Folgen
\begin{align}
a &= ( \; \; \; 0, 1, 2, 3, 4, ... ) \\
b &= (-1, 1, 3, 5, 7, ... )
\end{align}
von weiter oben an. Hier
ist die \(a\)-größer-Indexmenge gleich \( \{1\} \) (entsprechend der ersten Position),
die Gleich-Indexmenge ist \( \{2\} \) (entsprechend der zweiten Position)
und die \(b\)-größer-Indexmenge ist \( \{3, 4, 5, ...\} \).
Damit ist die Sache klar: nur die \(b\)-größer-Indexmenge ist unendlich groß,
so dass sie klar die Mehrheit der Indices umfasst. Also werden wir \( a < b \)
sagen.
Beim anderen Beispiel von oben mit den beiden Folgen
\begin{align}
a &= (1, 0, 1, 0, 1, 0, ... ) \\
b &= (0, 1, 0, 1, 0, 1, ... )
\end{align}
ist es dagegen schwieriger:
Die \(a\)-größer-Indexmenge umfasst die ungeraden Positionen,
die \(b\)-größer-Indexmenge umfasst die geraden Positionen und die Gleich-Indexmenge ist leer.
Man muss hier wohl einfach eine Wahl treffen. Details folgen später.
Insgesamt werden wir für alle denkbaren Indexmengen festlegen müssen, ob sie
eine Mehrheit der Indices repräsentieren oder nicht, also ob wir sie als dominant
ansehen wollen.
Die dominanten Indexmengen wollen wir dann in eine
Indexmengensammlung aufnehmen.
Dabei darf es zu keinen Widersprüchen kommen.
Beim Vergleich zweier beliebiger Zahlenfolgen \(a\) und \(b\) darf immer nur eine der drei Indexmengen
dominant sein und damit in unserer Sammlung vorkommen:
die \(a\)-größer-Indexmenge, die \(b\)-größer-Indexmenge oder
die Gleich-Indexmenge. Nur so ist sichergestellt,
dass \(a\) eindeutig größer, kleiner oder gleich \(b\) ist.
Schauen wir uns an, was für Eigenschaften eine solche Indexmengensammlung haben muss
und ob es sie überhaupt gibt.
Ein erster Hinweis ist die Forderung, dass eine Folge zu sich selber gleich sein
soll (Reflexivität):
\( a = a \).
In diesem Fall ist die Gleich-Indexmenge einfach die Menge der natürlichen Zahlen.
Die natürlichen Zahlen müssen also auf jeden Fall in unserer Indexmengensammlung
vorkommen, denn eine noch dominantere Indexmenge gibt es nicht.
Eine andere Forderung, die der Begriff Gleichheit erfüllen sollte,
ist die Symmetrie: Wenn \( a = b \) ist, so ist auch \( b = a \).
Das ist aber automatisch erfüllt. Insofern lernen wir hier
nichts Neues über die Indexmengensammlung.
Interessanter ist die Transitivität bei drei Folgen:
Wenn \( a = b \) und \( b = c \) ist,
so soll auch \( a = c \) sein.
Statt gleich könnten wir auch kleiner oder größer nehmen.
Auch hier gilt die Transitivität und die folgende Argumentation verläuft in gleicher Weise.
Bezeichnen wir die Gleich-Indexmenge von \(a\) und \(b\) als \( I_{a=b} \) ,
analog die anderen beiden Gleich-Indexmengen
\( I_{a=c} \) und \( I_{b=c} \) ,
und schauen wir uns die Schnittmenge von \( I_{a=b} \) und \( I_{b=c} \) an.
An diesen Positionen sind sowohl die Folgenglieder von \(a\) und \(b\)
also auch die Folgenglieder von \(b\) und \(c\) gleich.
Damit sind an diesen Positionen auch die Folgenglieder von \(a\) und c gleich.
Die Schnittmenge von \( I_{a=b} \) und \( I_{b=c} \) ist also eine Teilmenge von \( I_{a=c} \)
(\(a\) und \(c\) können durchaus auch noch an weiteren Positionen übereinstimmen,
an denen \(a\) und \(b\) oder \(b\) und \(c\) nicht gleich sind).
Anders gesagt: \( I_{a=c} \) ist eine Obermenge der Schnittmenge von \( I_{a=b} \) und \( I_{b=c} \).
Wir gehen daher auf Nummer Sicher und nehmen für zwei Indexmengen aus unserer Sammlung
auch deren Schnittmenge und alle Obermengen dieser Schnittmenge in unsere Sammlung auf.
Die Schnittmenge zweier dominanter Indexmengen soll also auch dominant sein und alle
Obermengen dieser Schnittmenge ebenfalls.
Die Forderung bezüglich der Obermengen können wir noch etwas umformulieren:
Betrachten wir irgendeine dominante Indexmenge \(I\) aus unserer Sammlung.
Neben \(I\) ist auch die Menge \( \mathbb{N} \) der natürlichen Zahlen in unserer Sammlung enthalten
(denn \( \mathbb{N} \) ist eine Obermenge zu jeder beliebigen Schnittmenge von dominanten Indexmengen).
Dann muss auch die Schnittmenge von \(I\) und \( \mathbb{N} \) und alle ihre Obermengen in der Sammlung
enthalten sein. Nun ist die Schnittmenge von \(I\) und \( \mathbb{N} \) nichts anderes als \(I\) selbst.
Also müssen für jede Indexmenge \(I\) aus unserer Sammlung
auch alle Obermengen von \(I\) in der Sammlung enthalten sein.
Das entspricht unserer Intuition: Wenn eine Indexmenge \(I\) eine Mehrheit der Indices
umfassen soll, so tun dies die Obermengen von \(I\) erst recht.
Wäre die leere Menge eine geeignete dominante Indexmenge?
Wohl kaum, denn dann wäre mindestens eine der beiden anderen Indexmengen,
die beim Folgenvergleich auftreten, unendlich groß und sollte den Titel der
dominanten Indexmenge erhalten.
Wir fordern also, dass die leere Menge nicht zu unserer Indexmengensammlung gehört.
Daraus ergibt sich eine wichtige Konsequenz. Nehmen wir an, eine Indexmenge \(I\)
gehört zu unserer Sammlung.
Wir können nun das Komplement von \(I\) bilden, also die Menge aller natürlichen Zahlen,
die nicht in \(I\) sind. Nennen wir diese Menge \(I_c\).
Darf \(I_c\) auch zu unserer Sammlung gehören?
Stellen wir uns dazu vor, die Gleich-Menge beim Vergleich zweier Folgen \(a\) und \(b\) wäre leer,
d.h. die beiden Folgen wären an keiner Position gleich.
Dann ist die \(a\)-größer-Indexmenge gerade das Komplement der \(b\)-größer-Indexmenge.
Nur eine von beiden soll aber die Mehrheit der Indices repräsentieren und
damit den Ausschlag geben. Wenn also \(I\) zu unserer Mehrheits-Indexmengensammlung
dazugehört, so darf das Komplement \(I_c\) nicht dazugehören.
\(I\) und \(I_c\) dürfen nicht beide zugleich dominant sein.
Ein anderes Argument ist:
Die Schnittmenge von \(I\) und \(I_c\) ist die leere Menge.
Sie müsste nach dem oben Gesagten zu unserer Sammlung dazugehören, um die
Transitivität des Gleichheitsbegriffs sicherzustellen. Wir wollen aber nicht,
dass die leere Menge dazugehört. Wenn also eine Indexmenge \(I\) zu unserer Sammlung
gehört, dann darf ihr Komplement \(I_c\) nicht dazugehören.
Wir können daher beispielsweise nicht die geraden und die ungeraden Zahlen zugleich als
dominante Indexmengen in unserer Sammlung aufnehmen. Das hatten wir oben an einem Beispiel
bereits gesehen.
Wir wollen sogar noch einen Schritt weiter gehen und sagen, dass
bei jeder Teilmenge \(I\) der natürlichen Zahlen immer entweder diese Menge \(I\)
oder ihr Komplement \(I_c\) zu unserer Sammlung gehört.
Teilen wir also die natürlichen Zahlen komplett in zwei beliebige Teilmengen auf,
so ist stets einer dieser beiden Teile dominant, repräsentiert also die Mehrheit der natürlichen Zahlen.
Nur so ist garantiert, dass beim Vergleich zwei Folgen \(a\) und \(b\) immer
entweder die \(a\)-größer-Menge oder die \(b\)-größer-Menge oder die Gleich-Menge die Mehrheit der
Indices repräsentiert, also den Ausschlag beim Größenvergleich gibt.
Hier die Begründung:
Teil 1: Mindestens eine der drei Mengen
(\(a\)-größer-Menge oder die \(b\)-größer-Menge oder die Gleich-Menge)
ist in der Indexsammlung enthalten, also dominant, wie die folgende Fallunterscheidung zeigt:
Fall 1: die Gleich-Menge ist enthalten → fertig
Fall 2: die Gleich-Menge ist nicht enthalten,
also ist das Komplement der Gleich-Menge (also die Vereinigung der
\(a\)-größer-Menge und der \(b\)-größer-Menge) enthalten:
Fall 2.1: die \(a\)-größer-Menge ist enthalten → fertig
Fall 2.2: die \(a\)-größer-Menge ist nicht enthalten.
Dann ist ihr Komplement (die Vereinigung von \(b\)-größer-Menge und Gleich-Menge) enthalten.
Außerdem ist bei Fall 2 auch die Vereinigung der
\(a\)-größer-Menge und der \(b\)-größer-Menge enthalten.
Dann muss auch die Schnittmenge dieser beiden Vereinigungsmengen enthalten sein, also die \(b\)-größer-Menge
→ fertig
Teil 2: Zwei der drei Mengen (oder gar alle drei Mengen) zugleich können nicht enthalten sein.
Denn angenommen, die \(a\)-größer-Menge und die \(b\)-größer-Menge wären zugleich enthalten.
Dann wäre auch jede ihrer Obermengen enthalten, also beispielsweise
die Vereinigung der \(a\)-größer-Menge mit der Gleich-Menge. Sie ist aber das Komplement der
\(b\)-größer-Menge und darf nicht zugleich mit der \(b\)-größer-Menge enthalten sein.
Die Sache sieht also schon recht gut aus. Unsere Bedingungen an die Sammlung dominanter Indexmengen
garantieren, dass beim Vergleich zweier Folgen genau eine der drei Indexmengen dominant ist und
somit den Vergleich festlegt, sodass entweder eine der beiden Folgen größer als die andere ist
oder beide Folgen gleich groß sind.
Eine letzte Frage bleibt zu klären: Darf eine Indexmenge mit nur endlich vielen
natürlichen Zahlen zu unserer Sammlung gehören?
Wollen wir also beispielsweise, dass zwei unendliche Zahlenfolgen als gleich gelten können,
obwohl sie nur an endlich vielen Stellen übereinstimmen?
Intuitiv würden wir das wohl ausschließen, denn eine endliche Indexmenge kann ja wohl kaum
die Mehrheit bei unendlich vielen Indices darstellen.
Schauen wir uns aber trotzdem an, was geschieht,
wenn wir eine endliche Indexmenge in unserer Sammlung zulassen,
beispielsweise die Menge \(I = \{ 1, 2, 3 \} \) .
Dann muss unsere Sammlung auch mindestens eine der 1-Element-Mengen
\( \{1\} \), \( \{2\} \) oder \( \{3\} \) enthalten, und zwar aus folgendem Grund:
Nehmen wir an, unsere Sammlung enthielte \(I = \{ 1, 2, 3 \} \) ,
aber keine der drei 1-Element-Mengen. Dann müsste unsere Sammlung das Komplement jeder der drei
1-Element-Mengen enthalten, also die Menge aller natürlicher Zahlen außer 1, die
Menge aller natürlicher Zahlen außer 2 und die Menge aller natürlicher Zahlen außer 3.
Auch die Schnittmenge dieser drei Komplement-Mengen müsste dann enthalten sein,
also die Menge aller natürlicher Zahlen außer 1, 2 und 3.
Das ist aber gerade das Komplement von \(I\), das nicht zugleich mit \(I\)
in unserer Sammlung enthalten sein darf.
Die Annahme, \(I\) sei enthalten, aber keine der drei 1-Element-Mengen, führt also zu einem Widerspruch.
Folglich ist mit \(I = \{ 1, 2, 3 \} \) auch mindestens eine der drei 1-Element-Mengen
\( \{1\} \), \( \{2\} \) oder \( \{3\} \) in unserer Indexsammlung enthalten, also dominant.
Das Argument gilt ganz allgemein: lassen wir endliche Mengen wie beispielsweise das obige \(I\)
in unserer Sammlung zu, so ist auch mindestens eine 1-Element-Menge in unserer Sammlung enthalten.
Das hat aber verheerende Konsequenzen für unsere Definition der Gleichheit von Zahlenfolgen:
Wenn zwei Folgen ausschließlich an der einen Position übereinstimmen,
die durch die 1-Element-Indexmenge vorgegeben wird,
so wären sie damit schon gleich.
Wenn wir das zulassen würden, so wären konstante und nicht konstante Zahlenfolgen
gleichwertig und wir würden jegliche Grundlage verlieren, um unendlich kleine und unendlich große
Objekte zu modellieren. Unser Modell könnte nur die Eigenschaften der reellen Zahlen
darstellen, und dafür brauchen wir es nicht. Wir sagen also:
Um unsere angestrebte Interpretation der Zahlenfolgen zu erreichen, schließen
wir 1-Element-Mengen und damit auch alle endlichen Indexmengen von unserer Sammlung aus.
Endliche Indexmengen sind nicht dominant.
Unsere Indexmengen-Sammlung enthält nur unendlich große Teilmengen der natürlichen Zahlen.
Es geht sogar noch weiter: Da die endlichen Indexmengen alle nicht dominant sind,
müssen alle ihre Komplemente dominant sein, denn wir hatten gefordert:
Bei jeder gegebenen Menge ist entweder diese Menge oder ihr Komplement
dominant. Also gilt sogar:
Unsere Indexmengen-Sammlung enthält alle unendlich großen Teilmengen der natürlichen Zahlen,
bei denen nur endlich viele natürliche Zahlen fehlen.
Vorsicht: Dies bedeutet nicht, dass unsere Sammlung alle unendlichen Teilmengen
der natürlichen Zahlen enthält. So können nicht zugleich die geraden und die ungeraden
Zahlen enthalten sein, denn ihre Schnittmenge ist leer.
Die unendlichen Mengen in unserer Sammlung müssen sich alle so überschneiden, dass
ihre Schnittmengen ebenfalls unendlich groß sind!
Damit ist unsere Bedingungsliste an unsere Sammlung dominanter Indexmengen komplett.
Diese Sammlung von Indexmengen ist selbst eine Menge im Sinn der Mengenlehre
und man bezeichnet sie als freien Ultrafilter
über den natürlichen Zahlen.
Fassen wir zusammen:
Freie Ultrafilter als Sammlung dominanter Indexmengen:
Unsere Sammlung dominanter Indexmengen, die beim Vergleich reeller Zahlenfolgen
den Ausschlag geben sollen,
ist ein sogenannter freier Ultrafilter.
Das ist eine Menge (nennen wir sie \(F\) ), die Teilmengen der natürlichen Zahlen als Elemente enthält
und die folgende Eigenschaften besitzt (im Folgenden sind \(I, I'\) usw.
jeweils Indexmengen, also Teilmengen der natürlichen Zahlen):
Die Menge der natürlichen Zahlen ist in \(F\) enthalten:
\[ \mathbb{N} \in F \]
Wenn zwei Indexmengen \(I\) und \(I'\) in \(F\) enthalten sind, so ist auch ihre Schnittmenge
in \(F\) enthalten:
\[
(I \in F) \land (I' \in F ) \Rightarrow (I \cap I') \in F
\]
Wenn eine Indexmenge \(I\) in \(F\) enthalten ist, so sind auch
alle ihre Obermengen in \(F\) enthalten:
\[
(I \in F) \land (I \subseteq I') \Rightarrow (I' \in F)
\]
Nehmen wir eine beliebige Indexmenge \(I\) sowie
ihr Komplement \(I_c\). Dann ist genau eine dieser beiden
Indexmengen in \(F\) enthalten (und die andere nicht).
Das gilt für jede beliebige Teilmenge \(I\) der natürlichen Zahlen!
Die Indexmengensammlung \(F\) enthält keine endlichen Mengen, auch nicht die leere Menge.
Endliche Mengen sowie die leere Menge sind nicht dominant.
Insbesondere enthält daher \(F\) alle unendlichen Indexmengen, bei denen nur endlich viele
natürliche Zahlen fehlen.
Wenn nur die ersten drei Bedingungen erfüllt sind und wenn man die fünfte
Bedingung so abschwächt, dass nur die leere Menge nicht in \(F\) enthalten sein darf,
so nennt man \(F\) einen Filter. Wenn Bedingung 4 (die Komplement-Bedingung) hinzukommt,
so ist \(F\) ein Ultrafilter.
Zu einem Ultrafilter kann man keine weiteren Indexmengen mehr hinzufügen,
denn deren Komplement wäre ja schon im Ultrafilter enthalten, und nur eine der beiden Mengen
darf nach Bedingung 4 dabei sein (sonst würde deren Schnittmenge ja die leere Menge ergeben,
die ausgeschlossen ist). Daher nennt man einen Ultrafilter auch einen maximalen Filter.
Und wenn man jetzt noch die endlichen Mengen ausschließt,
so ist \(F\) ein freier Ultrafilter.
Noch eine kurze Nebenbemerkung: Was geschieht, wenn man die endlichen Mengen nicht ausschließt,
also einen nicht-freien Ultrafilter betrachtet?
Oben hatten wir es bereits erwähnt: Es muss dann mindestens eine 1-Element-Menge (nennen
wir sie \(\{a\}\)) dazu gehören. Dann gehören nach Bedingung 3 auch die entsprechenden Obermengen dazu,
also sind alle Mengen mit \(a\) als Element im nicht-freien Ultrafilter enthalten.
Die entsprechenden Komplementmengen sind dann genau die Mengen, die \(a\) nicht als Element enthalten.
Sie gehören wegen Bedingung 4 nicht zum Ultrafilter hinzu. Also ist der nicht-freie Ultrafilter
gerade die Menge aller Mengen, die \(a\) als Element enthalten:
\[ F =
\{ I \subseteq \mathbb{N} :\, a \in I \}
\]
Wir werden später noch sehen, dass man nur die nicht-freien Ultrafilter explizit
(nämlich so) hinschreiben kann. Die freien Ultrafilter (also die ohne endliche Mengen)
kann man dagegen nicht explizit mithilfe einer mathematischen Formel wie oben
hinschreiben. Hoffentlich existieren sie dennoch,
denn genau diese freien Ultrafilter brauchen wir!
Der Größenvergleich zwischen unendlichen reellen Zahlenfolgen ist nun mit
Hilfe eines freien Ultrafilters so definiert
(wie wir bereits von oben wissen):
Größenvergleich von Folgen:
Wir starten mit einem einmal gewählten freien Ultrafilter \(F\).
Dieser Ultrafilter enthält alle Indexmengen, die wir als dominant
ansehen wollen. Dann gilt für zwei reelle Zahlenfolgen \(a\) und \(b\) aus \(\mathbb{R}^\mathbb{N}\):
\( a = b \) genau dann, wenn die Gleich-Indexmenge im Ultrafilter \(F\) liegt
(die Gleichmenge ist die Indexmenge \(I\),
so dass für alle Indices \(i \in I\) gilt: \( a_i = b_i \) ).
\( a < b \) genau dann, wenn die \(b\)-größer-Indexmenge im Ultrafilter \(F\) liegt
(die \(b\)-größer-Menge ist die Indexmenge \(I\),
so dass für alle Indices \(i \in I\) gilt: \( a_i < b_i \) ).
\( a > b \) genau dann, wenn die \(a\)-größer-Indexmenge im Ultrafilter \(F\) liegt
(die \(a\)-größer-Menge ist die Indexmenge \(I\),
so dass für alle Indices \(i \in I\) gilt: \( a_i > b_i \) ).
Die Eigenschaften des Ultrafilters \(F\) garantieren, dass genau eine der drei Indexmengen
in \(F\) liegt und damit dominant gegenüber den beiden anderen Indexmengen ist.
Die dominante Indexmenge legt also das Größenverhältnis der Zahlenfolgen fest.
Bevor wir weitergehen, schauen wir uns zwei Beispiele an.
Erstes Beispiel:
\begin{align}
a &= (0, 0, 0, 9, 9, 6, 7, 8, 9, 10, 11, ... ) \\
b &= (9, 9, 9, 0, 0, 6, 7, 8, 9, 10, 11, ... )
\end{align}
Sind diese beiden Folgen gleich?
In den ersten 5 Positionen sind sie verschieden, aber ab Position 6 sind sie identisch.
Die Gleich-Indexmenge \( \{ 6, 7, 8, 9, ... \} \) ist in unserem
Ultrafilter \(F\) enthalten, denn sie ist das Komplement einer endlichen Menge.
Also ist \(a = b\).
Das zweite Beispiel kennen wir bereits von oben:
\begin{align}
a &= (1, 0, 1, 0, 1, 0, ... ) \\
b &= (0, 1, 0, 1, 0, 1, ... )
\end{align}
Diese beiden Folgen stimmen an keiner Position überein.
Die Gleichmenge ist die leere Menge, die \(a\)-größer-Menge sind die ungeraden Zahlen,
und die \(b\)-größer-Menge sind die geraden Zahlen. Nur eine von beiden Mengen
kann in unserem Ultrafilter enthalten sein. Es kommt hier also auf den Ultrafilter an,
ob wir \(a < b\) oder \(a > b\) haben. Zum Glück
spielt das aber keine entscheidende Rolle für die Modellierung der unendlichen Objekte.
Solange wir den einmal gewählten Ultrafilter für alle Größenvergleiche beibehalten,
sind die Größenverhältnisse in sich konsistent, und das ist der entscheidende Punkt.
Bei den meisten Größenvergleichen, die uns interessieren, ist sowieso nur eine der
drei Indexmengen (\(a\)-größer-, \(b\)-größer- oder Gleich-Indexmenge)
unendlich groß,
während die anderen beiden Indexmengen endlich sind. In der unendlich großen Indexmenge
fehlen dann nur endlich viele natürliche Zahlen. Von oben wissen wir, dass diese Indexmengen
immer dominant sind, also in jedem freien Ultrafilter enthalten sind.
Daher spielt die Wahl des Ultrafilters für diese Größenverhältnisse keine Rolle.
Existenz von freien Ultrafiltern
Eine entscheidende Frage haben wir bisher noch gar nicht beantwortet:
Gibt es solche Indexmengensammlungen wie oben gefordert überhaupt?
Oder anders gefragt:
Existieren freie Ultrafilter, und wenn ja, sind sie eindeutig?
Das ist gar nicht so leicht intuitiv zu beantworten.
Oben hatten wir sogar bereits angedeutet, dass man freie Ultrafilter nicht explizit
hinschreiben kann.
Unsere Indexmengensammlungen (ein freier Ultrafilter)
ist ein kompliziertes Objekt: Sie enthält nur unendliche Teilmengen der
natürlichen Zahlen.
Dabei enthält sie alle Teilmengen, bei denen nur endlich viele natürliche Zahlen fehlen,
denn die endlichen Komplemente sind ausgeschlossen.
Wie aber sieht es mit den unendlichen Teilmengen der natürlichen Zahlen aus,
deren Komplemente ebenfalls unendlich sind?
Von diesen Mengen darf unsere Sammlung nur entweder die Menge oder ihr Komplement enthalten.
Es müssen also auch unendliche Mengen ausgeschlossen werden, beispielsweise entweder die geraden
oder die ungeraden Zahlen.
Starten wir mit den Indexmengen, von denen wir wissen, dass sie in jedem freien Ultrafilter
enthalten sein müssen: die unendlichen Indexmengen, bei denen
höchstens endlich viele natürliche Zahlen fehlen.
Bezeichnen wir die Menge all dieser Indexmengen mit \(H\).
Dann ist \(H\) eine Teilmenge unseres freien Ultrafilters \(F\) (falls \(F\) existiert).
\(H\) ist ein Filter, denn es
erfüllt die erste, zweite, dritte und fünfte Bedingungen aus unserer Liste oben.
Einzig die vierte Bedingung ist nicht erfüllt:
Nicht bei jeder beliebigen Indexmenge \(I\)
ist entweder diese Menge oder ihr Komplement in \(H\) enthalten.
So gehören weder die geraden noch die ungeraden Zahlen zu \(H\).
Wir können lediglich sagen: Wenn eine Menge zu \(H\) gehört, dann gehört
ihr Komplement nicht zu \(H\), denn das Komplement ist eine endliche Indexmenge.
Gehen wir nun einen Schritt weiter und nehmen einige der noch fehlenden unendlichen
Indexmengen zu \(H\) hinzu, deren Komplement ebenfalls unendlich ist.
Dabei wollen wir aber beachten, dass die so erweiterte Menge ein Filter
bleibt, d.h. die Bedingungen 1 bis 3 sowie die ausgeschlossene leere Menge
wollen wir beibehalten. Wegen Bedingung 2 und der ausgeschlossenen leeren Menge
dürfen wir neue Indexmengen nur dann hinzunehmen, wenn deren Komplemente nicht schon
in der Sammlung enthalten sind. Ansonsten könnten wir nämlich aus einer Indexmenge
und ihrem Komplement per Schnittmenge die leere Menge erzeugen, die aber ausgeschlossen sein soll.
Damit sind natürlich auch endliche Indexmengen ausgeschlossen, denn deren Komplemente sind alle
bereits in \(H\) enthalten. Bedingung 5 ist also komplett erfüllt.
Als Beispiel können wir die geraden Zahlen zur Indexmengensammlung \(H\) hinzunehmen.
Damit die Filterbedingungen erfüllt bleiben, müssen wir zugleich auch alle Obermengen
der geraden Zahlen mit hinzunehmen sowie sämtliche mit all diesen Mengen
konstruierbaren Schnittmengen und deren Obermengen. Das sind sehr viele Mengen, die
wir hinzunehmen müssen, aber noch lange nicht alle Indexmengen.
Beispielsweise fehlt immer noch die Menge der Vielfachen von 4, also die Menge
\( \{ 4, 8, 12, 16, ... \} \).
Man darf nicht vergessen: es gibt sehr viele Teilmengen der natürlichen Zahlen.
Es sind nicht nur unendlich viele, sondern es sind sogar überabzählbar viele,
wie man mit dem Cantorschen Diagonalverfahren leicht zeigen kann.
Man kann sagen, die Teilmengen der natürlichen Zahlen bilden ein Kontinuum
von Mengen, so wie die reellen Zahlen ein Zahlenkontinuum bilden
(siehe das Potenzmengenaxiom in Kapitel 4.2).
Die Beweisidee ist nun klar:
Wenn wir immer weiter neue Indexmengen hinzunehmen und dabei die Filterbedingungen beachten,
dann hoffen wir, dass wir
irgendwann keine weiteren Indexmengen mehr in die Sammlung aufnehmen können, ohne
dabei die Filterbedingungen zu verletzen.
Wir wären dann fertig, denn Bedingung 4 wäre erfüllt:
Zu jeder beliebigen Indexmenge wäre entweder diese Menge oder ihr
Komplement in unserem Filter enthalten und wir hätten einen freien Ultrafilter.
Leider ist es nicht möglich, in abzählbarer Weise Stück für Stück
die fehlenden Indexmengen in die Sammlung aufzunehmen, denn wir haben es mit einem
überabzählbaren Kontinuum von Mengen zu tun. Intuitiv ist nicht zu erkennen,
ob die Hinzunahme von Mengen irgendwann einmal zu einem Ende kommt oder nicht.
Schauen wir uns die Menge \(M\) aller Filter an, die sich durch Hinzufügen von Mengen aus \(H\)
erzeugen lassen. Diese Filter können wir in gewissem Sinn nach der Größe ordnen.
Wir können sagen, ein Filter \(F\) ist kleiner als ein Filter \(F'\),
wenn \(F\) eine echte Teilmenge
von \(F'\) ist (also \(F'\) mindestens eine Indexmenge mehr als \(F\) enthält).
Analog sagen wir, \(F\) ist kleiner-gleich \(F'\), wenn \(F\) eine Teilmenge von \(F'\) ist
(dabei ist \(F = F'\) zugelassen).
Statt \(F \subset F' \) schreiben wir also auch \(F < F' \) und
statt \(F \subseteq F' \) schreiben wir auch \(F \leq F'\).
Die Menge \(M\) aller aus \(H\) erzeugten Filter ist
halbgeordnet
(man dagt auch partiell geordnet).
Diesen Begriff kennen wir schon aus Kapitel 4.2.
Er besagt, dass es Filterpaare gibt, bei denen wir sagen können,
welcher von beiden der größere ist (nämlich wenn der kleinere Filter
eine echte Teilmenge des größeren Filters ist).
Wir können aber nicht alle Filter aus \(M\) streng der Größe nach ordnen, so wie man die natürlichen Zahlen
ordnen kann. Wir können nämlich nicht für jedes Filterpaar \(F\) und \(F'\) aus \(M\) angeben,
ob \(F \leq F' \) oder \( F' \leq F \) ist.
Die beiden Filter \(F\) und \(F'\) können ja einfach verschieden sein, ohne dass einer davon
Teilmenge des anderen ist.
Aber wir können passende Teilmengen aus \(M\) herausgreifen,
so dass wir die Filter in dieser Teilmenge streng nach der Größe ordnen können.
Man sagt, dass die Filter in einer solchen Teilmenge
total geordnet sind. Bei jedem Filterpaar \(F\) und \(F'\) aus einer total geordneten
Teilmenge können wir dann angeben, welches der größere Filter ist (wir setzen voraus,
dass \(F\) ungleich \(F'\) ist).
Die Filter bilden gleichsam eine nach rechts aufsteigende Kette
\[
... < F < F' < F'' < ...
\]
wobei bei jedem Schritt nach rechts neue Indexmengen in den jeweiligen Filter aufgenommen
werden.
Daher bezeichnen wir eine solche total geordnete Teilmenge von \(M\)
selbst auch als Kette.
Für die Aufnahme neuer Indexmengen auf dem Weg nach rechts kommen
normalerweise verschiedene Mengensammlungen in Frage.
Es sind also viele verschiedene Ketten möglich.
Wir können aber alle Ketten mit der Menge \(H\) starten lassen, also mit dem Filter
aus allen unendlichen Indexmengen, bei denen
höchstens endlich viele natürliche Zahlen fehlen.
Die Ketten bilden also gleichsam einen sich nach rechts auffächernden Baum,
der die Filtermenge \(M\) durchzieht und der links mit der Menge \(H\) beginnt.
Einzelne Ketten können dabei auf ihrem Weg nach rechts auch an Knotenpunkten
wieder zusammenwachsen,
wenn in ihnen dieselben Indexmengen lediglich in verschiedener Reihenfolge
aufgenommen wurden. Jede Filtermenge kann also in vielen verschiedenen Ketten vorkommen.
Menge \(M\) aller Filter, die sich aus \(H\) durch Aufnahme weiterer Indexmengen
erzeugen lassen (die Filter werden durch blaue Kreise dargestellt). Dabei besteht \(H\)
aus allen unendlichen Indexmengen, bei denen
höchstens endlich viele natürliche Zahlen fehlen.
Jeder Pfeil bedeutet, dass weitere unendliche Indexmengen hinzugefügt werden, so dass
der Pfeil auf den jeweils größeren Filter zeigt.
Läuft man von \(H\) entlang einer Linie in Pfeilrichtung, so bilden alle Filtermengen,
an denen man dabei vorbeikommt, zusammen eine Kette.
Es gibt zu jeder Kette einen größten Filter (eine obere Schranke), nämlich
die Vereinigungsmenge aller Filter, die in der Kette vorkommen.
Jeder Filter in der Kette ist Teilmenge dieser
Vereinigungsmenge aller Filter der Kette, also kleiner-gleich dieser oberen Schranke.
Anmerkung: Damit ist keineswegs gesagt, dass die Kette nur endlich lang ist oder dass man diese
Vereinigungsmenge explizit hinschreiben kann.
Die Kette kann durchaus unendlich lang sein, aber sie endet (nach ggf. unendlich vielen Schritten)
an der Vereinigungsmenge aller Filter der Kette.
Halten wir fest:
Über die Menge \(M\) aller aus \(H\) erzeugten Filter:
Wir starten mit der Filtermenge \(H\) der unendlichen Indexmengen, bei denen
höchstens endlich viele natürliche Zahlen fehlen. Nun erweitern wir \(H\)
um weitere Indexmengen, so dass die so gewonnene
erweiterte Indexmengensammlung wieder ein Filter ist.
Mit \(M\) bezeichnen wir nun die Menge aller Filter, die sich so aus
H gewinnen lassen. Die Indexmengensammlungen in \(M\) enthalten also
wie \(H\) auf jeden Fall die unendlichen Indexmengen, bei denen
höchstens endlich viele natürliche Zahlen fehlen.
Daneben dürfen aber noch weitere
unendliche Indexmengen hinzukommen, solange die Filterbedingungen eingehalten werden
(also z.B. dürfen nie eine Indexmenge und ihr Komplement zugleich enthalten sein).
Die Menge \(M\) ist halbgeordnet, denn wir können die Teilmengenbeziehung zweier Filter
als kleiner-gleich-Beziehung ansehen:
Statt \(F \subseteq F' \) schreiben wir auch \(F\ \leq F' \).
In der Menge \(M\) können wir ausgehend von \(H\) Ketten bilden, indem wir schrittweise
immer weitere Indexmengen hinzunehmen und so immer größere Filter aufbauen.
Die Ketten sind damit total geordnete Teilmengen von \(M\).
Bei zwei beliebigen verschiedenen Filtern \(F\) und \(F'\) aus derselben Kette können wir angeben,
welches der größere Filter ist, wobei \(F < F'\)
bedeutet, dass \(F \subset F'\) ist.
Jede Kette in \(M\) besitzt eine obere Schranke, nämlich die
Vereinigungsmenge aller Filter der Kette.
Alle Filter in der Kette sind Teilmengen und damit
kleiner-gleich dieser oberen Schranke.
Und jetzt kommt der entscheidende Schritt:
Wir wenden das sogenannte Lemma von Zorn
aus der Zermelo-Fränkel-Mengenlehre mit Auswahlaxiom an (siehe Kapitel 4.2
und Kapitel 3.2):
Lemma von Zorn
Jede nichtleere halbgeordnete Menge, in der jede Kette
eine obere Schranke hat, enthält mindestens ein maximales Element
(d.h. in der halbgeordneten Menge gibt es kein Element, das größer als das maximale Element ist).
Unsere Menge \(M\) erfüllt genau diese Voraussetzungen. Also besitzt die Menge \(M\)
mindestens ein maximales Element. Das bedeutet:
In unserer aus \(H\) erzeugten Filtersammlung \(M\) gibt es mindestens einen Filter \(F_\mathrm{max}\),
der nicht mehr echte Teilmenge einer noch größeren Filtermenge in \(M\) sein kann.
Insbesondere kann man keine weitere Indexmenge mehr hinzufügen, ohne dass die
Filterbedingungen verletzt würden.
Reicht das aus, um zu erzwingen, dass bei jeder Indexmenge \(A\) entweder diese Menge
oder ihr Komplement \(A_c\) im maximalen Filter \(F_\mathrm{max}\)
enthalten sein muss (Bedingung 4)?
Nehmen wir dazu an, weder \(A\) noch \(A_c\) seien im maximalen Filter \(F_\mathrm{max}\) enthalten.
Dann könnten wir z.B. die Menge \(A\) zu \(F_\mathrm{max}\) hinzufügen.
Wenn wir nun diese erweiterte Menge zu einem neuen Filter
ausbauen können, so wäre dieser neue Filter größer als \(F_\mathrm{max}\) ,
und \(F_\mathrm{max}\) wäre nicht der maximale Filter – ein Widerspruch!
Also muss dann entweder \(A\) oder \(A_c\)
im maximalen Filter \(F_\mathrm{max}\) enthalten sein.
Überprüfen wir, ob wir \(F_\mathrm{max}\) nach
Hinzufügen von \(A\) zu einem größeren Filter
ausbauen können. Dazu müssen wir zumindest
alle Obermengen von \(A\) sowie alle Schnittmengen zwischen \(A\)
und den Mengen aus \(F_\mathrm{max}\) hinzufügen.
Das dürfen wir aber nur dann tun, wenn nicht bereits das Komplement einer dieser Mengen
in \(F_\mathrm{max}\) enthalten ist.
Um das zu überprüfen, hilft folgendes Bild:
Die Menge \( \mathbb{N} \) der natürlichen Zahlen zerfällt in
zwei überlappungsfreie Teile, nämlich
in \(A\) und \(A_c\).
Wenn wir also eine echte Obermenge von \(A\) bilden, müssen wir ein Stück von \(A_c\)
zu \(A\) herübernehmen:
Das Komplement der echten Obermenge von \(A\) ist
also eine echte Teilmenge von \(A_c\). Diese Teilmenge kann aber nicht im Filter \(F_\mathrm{max}\)
enthalten sein, denn sonst müssten alle ihre Obermengen einschließlich \(A_c\) selbst
in \(F_\mathrm{max}\) enthalten sein, und wir hatten ausgeschlossen, dass \(A_c\)
enthalten ist.
Also ist das Komplement einer echten Obermenge von \(A\) nicht im Filter \(F_\mathrm{max}\) enthalten
und wir können die Obermengen von \(A\) problemlos zu \(F_\mathrm{max}\) hinzufügen.
Ähnlich ist es bei den Schnittmengen von \(A\) mit Indexmengen aus \(F_\mathrm{max}\).
Nehmen wir eine Indexmenge aus \(F_\mathrm{max}\) heraus – nennen wir sie \(B\).
Wir wollen die Schnittmenge \( A \cap B \) hinzufügen und müssen dazu sicherstellen,
dass ihr Komplement \( (A \cap B)_c \) nicht enthalten ist.
Wenn \( (A \cap B)_c \) in \(F_\mathrm{max}\) enthalten wäre,
so müsste nach den Filtergesetzen auch ihre Schnittmenge mit \(B\) in \(F_\mathrm{max}\)
enthalten sein. Das ist gerade die Menge \( A_c \cap B \) (siehe Bild unten).
Diese Schnittmenge kann aber nicht in \(F_\mathrm{max}\)
enthalten sein, denn sonst müsste auch die Obermenge \(A_c\) enthalten sein.
Das Komplement \( (A \cap B)_c \) ist also nicht
in \(F_\mathrm{max}\) enthalten und wir können \( A \cap B \)
problemlos hinzufügen.
Wenn also weder \(A\) noch das Komplement \(A_c\) im maximalen Filter \(F_\mathrm{max}\)
enthalten wären, so
könnten wir \(A\) selbst sowie alle Obermengen von \(A\) und alle Schnittmengen zwischen \(A\)
und den Mengen aus \(F_\mathrm{max}\) hinzufügen und so \(F_\mathrm{max}\) zu einem größeren
Filter ausbauen. Damit wäre \(F_\mathrm{max}\) Teilmenge eines größeren Filters und
nicht mehr der maximale Filter – ein Widerspruch.
\(F_\mathrm{max}\) ist also nur dann ein maximaler Filter, wenn
entweder \(A\) oder das Komplement \(A_c\) darin enthalten ist.
Das gilt für jede beliebige Indexmenge \(A\).
Die Eigenschaft von \(F_\mathrm{max}\), nicht Teilmenge eines größeren
Filters zu sein, garantiert, dass Bedingung 4 erfüllt ist:
Bei jeder Indexmenge \(A\) ist entweder diese Menge oder ihr Komplement
\(A_c\) im maximalen Filter \(F_\mathrm{max}\) enthalten.
Damit ist \(F_\mathrm{max}\) der gesuchte freie Ultrafilter.
UFFFFF...... – das wäre geschafft!
Eindeutigkeit von freien Ultrafiltern
Wie sieht es mit der Eindeutigkeit eines freien Ultrafilters aus?
Die obige Vorgehensweise zeigt deutlich, dass es zwar nach dem Lemma von Zorn
mindestens einen freien Ultrafilter geben muss, aber dass dieser keineswegs eindeutig ist.
Ob beispielsweise die geraden oder die ungeraden Zahlen in dem freien Ultrafilter enthalten sind,
ist nicht festgelegt. Hier gibt es offenbar eine Wahlfreiheit bei der
Konstruktion des Ultrafilters.
Auf den ersten Blick ist es vielleicht verwirrend, dass es mehrere maximale Filter geben kann.
Aber wir dürfen nicht vergessen, dass die Menge \(M\) nicht total geordnet ist, sondern nur halbgeordnet.
Die verschiedenen maximalen Filter lassen sich also in ihrer Größe nicht vergleichen,
denn keiner von ihnen ist Teilmenge eines anderen.
Ist diese Nicht-Eindeutigkeit gefährlich für unser Vorhaben, unendlich kleine und große
Objekte zu konstruieren?
Das kommt darauf an, was wir von Mengen fordern.
Wir versuchen zwar, den Begriff der Menge intuitiv zu erfassen, aber
bei unendlichen Mengen stößt man hier schnell an die Grenzen der Anschauungskraft.
Wer kann sich schon ein überabzählbares Kontinuum von Mengen vorstellen,
so wie es die Menge aller denkbaren Indexmengen ist?
Ein freier Ultrafilter greift sich aber aus diesem Indexmengen-Kontinuum
unendlich viele Indexmengen heraus, wobei diese Auswahl durch die Filterbedingungen gesteuert wird.
Es ist daher nicht allzu überaschend, dass es eine Rolle spielt, was wir über das
Kontinuum von Mengen wissen oder annehmen. Erinnern wir uns an die
Kontinuumshypothese in Kapitel 4.3:
Kontinuumshypothese:
Es gibt keine Menge, die in ihrer Mächtigkeit zwischen den natürlichen Zahlen
und den reellen Zahlen (dem Kontinuum) liegt.
Aus Kapitel 4.3 wissen wir bereits, dass die Kontinuumshypothese
mit Hilfe der Zermelo-Fränkel-Axiome der Mengenlehre weder bewiesen noch
widerlegt werden kann. Die Axiome legen den Mengenbegriff einfach nicht
genau genug fest, um diese Frage beantworten zu können.
Wir müssen uns also entscheiden, was wir bei einem Kontinuum von
Mengen wie bei unseren Indexmengen zulassen wollen und was nicht.
Die Anschauung hilft uns hier leider nicht sonderlich weiter.
In Kapitel 4.3 hatten wir Möglichkeiten kennengelernt,
die Zermelo-Fränkel-Axiome so zu erweitern bzw. so abzuändern,
dass die Kontinuumshypothese und sogar das Auswahlaxiom bewiesen werden können:
Konstruierbarkeitsaxiom:
Wir verlangen, dass alle Mengen konstruierbar
im Sinne Gödels sind.
Zumindest im Reich der konstruierbaren Mengen können wir uns also
auf die Kontinuumshypothese und das Auswahlaxiom verlassen.
Wenn wir von unendlichen Mengen verlangen, dass die Kontinuumshypothese gilt,
dann kann man zeigen, dass es keine Rolle spielt, welchen freien Ultrafilter
wir nehmen. Die verschiedenen Wahlmöglichkeiten für freie Ultrafilter
führen lediglich zu verschiedenen Schreibweisen für dieselben unendlichen Objekte.
Wenn wir dagegen die Kontinuumshypothese als unentscheidbar in der Schwebe lassen,
so bleibt auch die Frage in der Schwebe, ob die Wahlmöglichkeit bei den freien
Ultrafiltern eine Rolle spielt oder nicht. Es gibt hier also eine Freiheit
bei den mathematischen Denkmöglichkeiten und man muss sich letztlich entscheiden,
in welche Denkrichtung man weitergehen will.
Seit dem Gödelschen Unvollständigkeitssatz wissen wir ja:
Mathematische Systeme reichen nicht aus, um immer über die Wahrheit aller darin
formulierbaren Aussagen zu entscheiden.
So einen Fall haben wir wieder einmal vor uns!
Über das Lemma von Zorn und das Auswahlaxiom
Bei dem Beweis, dass es freie Ultrafilter gibt, haben wir oben das
Lemma von Zorn
verwendet. Demnach hat
jede nichtleere halbgeordnete Menge, in der jede Kette
eine obere Schranke hat, mindestens ein maximales Element.
Das obige Bild von \(M\), in der die blauen Kreise durch gelbe Pfeile zu Ketten aufgereiht werden,
lässt das Lemma von Zorn selbstverständlich erscheinen. Jede nach rechts laufende Kette
liefert ein maximales Element, denn alle untereinander vergleichbaren Elemente liegen
in einer gemeinsamen Kette.
Bei endlichen Mengen ist das also unmittelbar einleuchtend, aber bei unendlichen oder gar kontinuierlichen Mengen
könnte es Probleme geben. Eine genaue Analyse zeigt:
Das Lemma von Zorn ist im Rahmen der Zermelo-Fränkel-Mengenlehre
äquivalent (gleichwertig) zum Auswahlaxiom (siehe Kapitel 4.2).
Auswahlaxiom:
Gegeben sei eine beliebige Menge (ein Mengensystem) \(x\). Die in \(x\)
enthaltenen Mengen sollen alle nicht-leer
und paarweise disjunkt sein, also keine gemeinsamen Elemente enthalten.
Dann existiert eine Menge \(y\), die mit jeder in \(x\) enthaltenen Menge genau ein Element gemeinsam hat.
Das Auswahlaxiom
Die Menge \(y\) fischt also aus den in \(x\) enthaltenen Mengen jeweils genau ein Element heraus.
Das Axiom sagt, dass dieses Auswählen von je einem Element aus jeder in \(x\) enthaltenen Menge geht:
die Menge \(y\) existiert. Das Axiom sagt nicht, wie es geht, und in vielen Fällen ist es auch
nicht möglich, anzugeben, wie es gehen soll. Daher bezeichnet man das
Auswahlaxiom auch als nicht-konstruktiv.
Wir sind in Kapitel 3.2 und Kapitel 4.2
bereits auf die Probleme
mit dem Auswahlaxiom eingegangen.
So behauptet das Auswahlaxiom beispielsweise, dass man
aus allen nichtleeren Teilmengen der reellen Zahlen
jeweils genau ein Element auswählen kann.
Leider findet man keine allgemeine Methode, die bei allen
Teilmengen der reellen Zahlen funktioniert.
Die Teilmengen der reellen Zahlen sind beliebig komplexe Punktmengen aus dem
reellen Zahlenkontinuum, und man findet bei jeder Auswahlmethode eine Teilmenge,
bei der diese Auswahlmethode versagt.
Das Auswahlaxiom ist also gewissermaßen Glaubenssache.
Es legt eine wünschenswerte Eigenschaft von Mengen fest, die wir aber separat fordern müssen
und die wir nicht aus den anderen Zermelo-Fränkel-Axiomen herleiten können.
Fordert man das Auswahlaxiom oder lehnt man es ab, so entscheidet man sich jeweils
einfach für einen etwas anderen Mengenbegriff. Und wer auf dieser Welt weiß schon aus dem
Bauch heraus ganz präzise, was eine Menge genau ist?!
Wie man aus dem Auswahlaxiom das Lemma von Zorn herleiten kann, findet man
an vielen Stellen im Internet
(siehe z.B.
Matroids Matheplanet, Mathematik: Über das Auswahlaxiom oder auch
Stefan Kühnlein: Das Lemma von Zorn sowie
Wikipedia: Lemma von Zorn).
Erst hatte ich vor, den Beweis an dieser Stelle zu bringen, doch das hätte wohl den Rahmen dieses
sowieso schon recht langen Kapitels endgültig gesprengt.
Jedenfalls muss man im Beweis eine Funktion konstruieren, die aus einer Mengensammlung
jeweils ein Element pro Menge herausfischt. Damit lässt sich aus der Annahme, es gäbe kein maximales Element,
ein Widerspruch herleiten.
Das Lemma von Zorn ist also genauso glaubwürdig wie das Auswahlaxiom.
Im Grunde fordert man über das Auswahlaxiom die Existenz freier Ultrafilter gleichsam ein.
Das kennt man auch aus anderen Gebieten der Mathematik:
Um bei unendlich-dimensionalen Vektorräumen die Existenz einer Basis zu beweisen,
braucht man ebenfalls das Auswahlaxiom bzw. das Lemma von Zorn.
Freie Ultrafilter oder auch eine Basis unendlich-dimensionaler Vektorräume
existieren in dem Sinn, dass sich aus ihrer eingeforderten Existenz
kein Widerspruch zu den anderen Axiomen ergibt.
Akzeptiert man das Auswahlaxiom oder das gleichwertige Lemma von Zorn, so akzeptiert
man auch freie Ultrafilter oder eine Basis unendlich-dimensionaler Vektorräume
(aber auch andere etwas merkwürdige Konsequenzen, siehe Kapitel 3.2).
Man erhält aber keine Konstruktionsvorschrift, mit der man einen freien Ultrafilter
explizit hinschreiben könnte.
In früheren Zeiten hätte dies einige Mathematiker beunruhigt.
Heute ist man zumeist relativ abgebrüht, was die Existenz von nicht konstruierbaren Objekten betrifft.
Vielleicht ist ihre Existenz ja trotzdem nützlich?
Wenn man sich auf konstruierbare Mengen im Sinne des Konstruierbarkeitsaxioms von Gödel beschränkt,
so lösen sich all diese Unwägbarkeiten sowieso in Wohlgefallen auf.
Schließt man nicht-konstruierbare Mengen aus, so sind ja Auswahlaxiom und sogar Kontinuumshypothese beweisbar
und damit existieren auch freie Ultrafilter. Alle Gödel-konstruierbaren Mengen sind hinreichend gutartig,
so dass man immer Elemente aus ihnen herausfischen kann. Sie sind hinreichend gutartig, so dass
jede konstruierbare Indexmenge oder ihr Komplement garantiert in einem freien Ultrafilter
enthalten sind. Die Probleme entstehen erst, wenn wir mathematische Monstermengen zulassen.
Daher sollten wir nicht allzu beunruhigt sein: Solange es mathematisch einigermaßen gesittet zugeht,
werden wir es schaffen, alle notwendigen Indexmengen in einen Filter aufzunehmen und so
die Existenz eines freien Ultrafilters zu garantieren.
Trotz der Nichteindeutigkeit der
Ultrafilter werden dann die Objekte, die wir damit definieren werden, eindeutig sein (bis auf Isomorphien,
also Änderungen der Schreibweise). Machen wir uns also ans Werk!
Hyperreelle Zahlen
Halten wir kurz inne und sammeln, was wir bisher erreicht haben:
Wir wollen die reellen Zahlen um unendlich kleine und unendlich große Objekte erweitern.
Deshalb modellieren wir diese Objekte inklusive der reellen Zahlen durch unendliche reelle
Zahlenfolgen. Für den Vergleich zweier Zahlenfolgen \(a\) und \(b\) soll es entscheidend sein,
ob die \(a\)-größer-Indexmenge, die \(b\)-größer-Indexmenge oder die Gleich-Indexmenge
dominant ist, also in gewissem Sinn die Mehrheit der Indices repräsentiert.
Schritt für Schritt haben wir nun ermittelt, welche Eigenschaften
die Menge aller dominanten Indexmengen haben muss, und ob es eine solche Menge gibt.
Es kam heraus, dass die dominanten Indexmengen unendlich groß sein müssen,
dass nicht gleichzeitig eine Indexmenge und ihr Komplement dominant sein dürfen und
dass die Obermengen und alle Schnittmengen dominanter Indexmengen ebenfalls
dominant sein müssen.
Eine besondere Forderung war, dass bei jeder denkbaren Indexmenge entweder diese Menge
oder ihr Komplement dominant sein muss.
Eine Menge von Indexmengen mit diesen Eigenschaften haben wir freien Ultrafilter genannt.
Wir haben gezeigt, dass eine solche Indexmengensammlung tatsächlich existiert, wenn
wir das Auswahlaxiom bzw. das gleichwertige Lemma von Zorn voraussetzen.
Wenn also die denkbaren Mengen so gutartig sind, dass man aus jeder Mengensammlung pro Menge immer
genau ein Element herausfiltern kann, dann können wir sicher sein, dass es einen freien Ultrafilter gibt,
so dass bei jeder denkbaren Indexmenge entweder diese Menge
oder ihr Komplement in der Sammlung enthalten ist. Konkret hinschreiben können wir den
freien Ultrafilter allerdings nicht.
Es gibt unendlich viele freie Ultrafilter, also unendlich viele Möglichkeiten,
dominante Indexmengensammlungen zusammenzustellen. So müssen wir uns entscheiden, ob die geraden oder die
ungeraden natürlichen Zahlen dominant sein sollen.
Zum Glück kommt es auf die Wahl nicht an, wenn wir die Kontinuumshypothese akzeptieren
(was bei Gödel-konstruierbaren Mengen beispielsweise gegeben ist).
Bei anderen Indexmengen ist die Sache
dagegen eindeutig: Endliche Indexmengen sind nicht dominant, ihre Komplemente dagegen schon.
Nun sind wir endlich gerüstet, die gewünschten Objekte zu konstruieren.
Wir nennen diese Objekte hyperreelle Zahlen
und bezeichnen die Menge
der hyperreellen Zahlen mit \( ^*\mathbb{R} \).
Als Startpunkt müssen wir uns zunächst für einen freien Ultrafilter entscheiden, den wir
anschließend beibehalten werden. Damit ist dann der Größenvergleich von Zahlenfolgen festgelegt.
Zahlenfolgen, die wir im obigen Sinn als gleich ansehen, sollen dabei dieselbe
hyperreelle Zahl darstellen.
Auf diese Weise kann man die
Menge aller Zahlenfolgen \( \mathbb{R}^\mathbb{N} \)
in einzelne Gleichheits-Teilmengen aufteilen, wobei die Folgen in jeder
einzelnen Teilmenge untereinander gleich sein sollen
(sodass deren jeweilige Gleich-Indexmengen zu unserem freien Ultrafilter gehören,
also als dominant gewertet werden).
Diese Teilmengen bezeichnet man als Äquivalenzklassen.
Jede Folge in einer Äquivalenzklasse modelliert dieselbe hyperreelle Zahl.
Man sagt daher auch, die Äquivalenzklasse insgesamt modelliert die hyperreelle Zahl.
Die Menge der hyperreellen Zahlen ist dann gleichsam die Menge dieser
Äquivalenzklassen. Das hört sich geheimnisvoll an, bedeutet aber lediglich, dass wir aus
einer Äquivalenzklasse irgendeine Folge auswählen dürfen, um unsere hyperreelle Zahl darzustellen.
Dabei darf es keine Rolle spielen, welche Folge wir konkret nehmen.
So etwas kommt in der Mathematik öfter vor:
Auch bei Brüchen gibt es das, denn die Brüche 1/2 und 2/4 stellen dieselbe rationale Zahl dar.
Wie man mit hyperreellen Zahlen rechnet, haben wir oben bereits gesehen.
Beispielsweise addiert man hyperreellen Zahlen, indem man sich zwei entsprechende Folgen
nimmt und die Folgenglieder Position für Position addiert.
Analog funktionieren auch Subtraktion, Multiplikation und Division.
Welche Sorten hyperreeller Zahlen gibt es?
Da sind zunächst die konstanten Zahlenfolgen und die dazu gleichen (also gleichwertigen) Folgen.
Sie stellen die reellen Zahlen dar, die damit Teilmenge der hyperreellen Zahlen sind.
Wir hatten das oben bereits gesehen.
Neben den reellen Zahlen gibt es die infinitesimalen Zahlen, also die gewünschten
unendlich kleinen Objekte, die wir oben beispielsweise mit \(dx\) bezeichnet hatten.
Eine infinitesimale Zahl ist größer als jede negative reelle Zahl,
aber kleiner als jede positive reelle Zahl. Die Null zählt man also aus Gründen der Einfachheit
zu den infinitesimalen Zahlen hinzu. Unter den reellen Zahlen ist sie die einzige
infinitesimale Zahl. Unter den hyperreellen Zahlen gibt es dagegen
neben der Null noch unendlich viele weitere infinitesimale Zahlen. Genau das wollten wir erreichen!
Schauen wir uns ein Beispiel an:
\[
a = ( 1, \frac{1}{2}, \, \frac{1}{3}, \, \frac{1}{4}, \, \frac{1}{5}, \, ... )
\]
Diese hyperreelle Zahl ist größer als Null,
dargestellt beispielsweise durch die konstante Folge
\( 0 = (0, 0, 0, ... ) \), denn die \(a\)-größer-Indexmenge
sind die kompletten natürlichen Zahlen.
Sie ist aber kleine als jede positive reelle Zahl \(r\),
dargestellt beispielsweise durch die konstante Folge
\( r = (r, r, r, ... ) \), denn die \(r\)-größer-Indexmenge beginnt an der Position \(i\), an der
\( \frac{1}{i} < r \) wird ( \(r\) kann zwar beliebig klein sein, ist aber fest vorgegeben,
so dass \( \frac{1}{i} \) für genügend große \(i\) kleiner als \(r\) wird).
Damit fehlen in der \(r\)-größer-Indexmenge
nur endlich viele natürliche Zahlen, sie ist also dominant und in unserem freien Ultrafilter
garantiert enthalten.
Man beachte, dass im Sinne der Cauchyfolgen \(a\) gegen \(0\) konvergiert
und damit gleich \(0\) ist. Bei den so konstruierten reellen Zahlen
gibt es daher keine infinitesimalen Zahlen.
Beim Größenvergleich, wie er bei den hyperreellen Zahlen definiert ist,
ist das nun anders: \(a\) ist größer als \(0\). Der Unterschied in der
Konstruktion der reellen und
der hyperreellen Zahlen mit Hilfe von Zahlenfolgen liegt also in der Art begründet,
wie wir die Gleichheit festlegen. Die Bildung der
Äquivalenzklassen erfolgt in beiden Fällen unterschiedlich!
Neben dem obigen \(a\) gibt es natürlich noch unendlich viele weitere
infinitesimale Zahlen, beispielsweise
\[
b = ( 10, \, 1, \, \frac{1}{10}, \, \frac{1}{100}, \, \frac{1}{1000}, \, ... )
\]
Dabei ist die obige infinitesimale Zahl \(a\) größer als diese infinitesimale Zahl \(b\), denn
ab Position drei sind die Folgenglieder von \(a\) größer als die von \(b\).
Auch unter den infinitesimalen Zahlen gibt es also größere und kleinere Zahlen.
So ist beispielsweise auch \(2a\) größer als \(a\), obwohl beide kleiner als jede reelle Zahl sind.
Man kann sich gleichsam vorstellen, wie man auf der Zahlengeraden den Bereich um Null herum
unendlich stark vergrößert und so die infinitesimalen
Zahlen um Null herum sichtbar macht – diese Hilfsvorstellung
sollte man allerdings nicht allzu wörtlich nehmen.
Ganz analog gibt es unendliche Zahlen. Diese Zahlen sind entweder größer als jede positive
oder kleiner als jede negative reelle Zahl. So ist der Kehrwert der infinitesimalen
Folge \( a = ( 1, \frac{1}{2}, \, \frac{1}{3}, \, \frac{1}{4}, \, \frac{1}{5}, \, ... ) \)
von oben, also die Folge
\[
b = \frac{1}{a} = (1, 2, 3, 4, 5, ... )
\]
eine unendlich große Zahl.
Allgemein ist eine von \(0\) verschiedene Zahl \(x\) genau dann unendlich, wenn \(1/x\) infinitesimal ist.
Analog zu oben kann man sich vorstellen, dass man die unendlichen Zahlen
am positiven oder negativen Ende der Zahlengeraden mit einem unendlichen Fernrohr
sehen kann.
Neben den unendlichen und den infinitesimalen hyperreellen Zahlen gibt es weitere hyperreelle Zahlen,
die nicht zu den reellen Zahlen gehören, die aber dennoch nicht unendlich groß oder klein sind.
Ein Beispiel ist die Zahl
\[
b = ( 2, \, \frac{3}{2}, \, \frac{4}{3}, \, \frac{5}{4}, \, \frac{6}{5}, \, ... )
\]
Vermutlich haben sie es bereits erkannt: \(b\) ist einfach gleich 1 plus der infinitesimalen Zahl \(a\) von oben.
Bei den Cauchyfolgen wäre diese Folge gleichwertig zur konstanten 1er-Folge, d.h. \(b\) wäre gleich 1.
Bei den hyperreellen Zahlen ist das aber anders, denn \(b\) und die konstante 1er-Folge unterscheiden sich
an allen Positionen. Allerdings ist der Unterschied von \(b\) und 1 nur infinitesimal.
Man kann zeigen, dass jede endliche nicht-reelle hyperreelle Zahl
unendlich nah an einer eindeutigen reellen Zahl liegt. Jede endliche nichtreelle hyperreelle Zahl \(x\)
entsteht also aus einer bestimmten reellen Zahl durch Hinzuaddieren einer infinitesimalen Zahl.
Die reelle Zahl nennt man auch Standardteil von \(x\) und schreibt \( \mathrm{st}(x) \) (manchmal
sagt man statt Standardteil auch Schatten).
Die infinitesimale Zahl \( x - \mathrm{st}(x) \) nennt man entsprechend Nichtstandardteil
von \(x\). Manchmal bezeichnet man die infinitesimale Umgebung
einer reellen Zahl \(r\) auch als Halo von \(r\).
Das sind dann alle hyperreellen Zahlen, deren Standardteil \(r\) ist.
Man sagt auch, alle hyperreellen Zahlen im Halo von \(r\) sind fast gleich oder auch
infinitesimal benachbart. Für zwei fast gleiche Zahlen \(a\) und \(b\) schreibt man auch
\( a \simeq b \) , d.h. \( \mathrm{st}(a) = \mathrm{st}(b) \) bzw. \( a - b \) ist
infinitesimal.
Man kann sich vorstellen, dass man auf der Zahlengeraden den Bereich um eine reelle Zahl \(x\) herum
unendlich stark vergrößert und so die
infinitesimalen Zahlen um \(x\) (also den Halo von \(x\)) sichtbar macht,
beispielsweise hier die infinitesimale Zahl \( x + dx \).
Die Darstellung von infinitesimalen Zahlen durch immer kleiner werdende Folgen
entspricht letztlich der intuitiven Vorstellung, die Archimedes, Leibniz und Newton wohl
geleitet hat. Man stellt sich vor, wie eine Zahl immer kleiner wird, ohne jedoch jemals
gleich Null zu werden. Analog ist es bei den unendlichen Zahlen.
Nur hat die Mathematik leider ein Problem damit, diese Vorstellung
unmittelbar zu formalisieren. Sie schafft es nur dadurch, dass sie in einer einzigen Aussage sämtliche
Zwischenschritte, die beim Kleiner-Werden auftreten, auf einmal erfasst.
Im \( \epsilon - \delta \) -Formalismus gelingt das durch
die Formulierung Für alle positiven \( \epsilon \) ... ,
die auch beliebig kleine positive ε umfasst.
Bei den hyperreellen Zahlen gelingt das, indem man alle Zwischenschritte in unendlichen Zahlenfolgen aufnimmt,
deren Folgenglieder beliebig klein werden können. Hier nutzt man die Fähigkeit der Mengenlehre, auch
mit unendlichen Mengen umgehen zu können. In diesem Sinn
arbeitet die Zahlenfolgen-Formulierung der hyperreellen
Zahlen mit aktualen Unendlichkeiten (nämlich mit unendlich langen Zahlenfolgen),
während die \( \epsilon - \delta \) -Formulierung vielleicht eher mit potentiellen Unendlichkeiten
arbeitet: ich kann \( \epsilon \) beliebig klein machen, muss aber letztlich
immer einen endlichen Wert wählen.
Aber auch in der \( \epsilon - \delta \) -Formulierung sorgt die
Formulierung Für alle positiven \( \epsilon \) ...
über die Logik und die Mengenlehre dann letztlich doch für eine aktuale Unendlichkeit, denn
es wird über die unendliche Menge der positiven reellen Zahlen quantifiziert.
Unter dem Strich leisten also beide Formulierungen dasselbe. Für Physiker und Ingenieure ist es aber immerhin
beruhigend, dass dank der hyperreellen Zahlen
ihre geliebten infinitesimalen Objekten eine Rehabilitation erfahren haben, die auch mathematische Puristen
zufriedenstellen kann.
Funktionen in den hyperreellen Zahlen
Funktionen spielen in der normalen Analysis eine wichtige Rolle.
Wenn wir die Analysis mit Hilfe der hyperreellen Zahlen formulieren wollen,
so werden wir auch dort Funktionen benötigen. Wir werden wissen müssen,
was \( f(x + dx) \) bedeuten soll, wobei \(x\) eine reelle Zahl und \(dx\) eine
infinitesimale Zahl ist.
Nehmen wir als Beispiel die reelle Sinusfunktion \( \sin(x) \).
Wie würden wir diese Funktion in die hyperreellen Zahlen übertragen?
Nennen wir die so übertragene Funktion \( ^*\sin(x) \).
Was soll dann \( \sin(dx) \) mit
\[
dx = (1, \, \frac{1}{2}, \, \frac{1}{3}, \, ... )
\]
sein?
Am einfachsten wäre es, wie bei den Grundrechenarten auch hier einfach komponentenweise
vorzugehen:
\[
^*\sin(dx) = ( \sin(1), \, \sin(1/2), \, \sin(1/3), \, ... )
\]
Da die Sinusfunktion für alle reellen Zahlen definiert ist, wäre das kein Problem.
Analog könnten wir bei allen Funktionen \(f\) vorgehen, die für alle reellen Zahlen definiert sind:
\[
^*f(x) = (f(x_1), \, f(x_2), \, f(x_3), \, ... )
\]
mit der hyperreellen Zahl \( x = (x_1, x_2, x_3, ... ) \).
Den * vor dem Funktionsnamen lassen wir dabei oft auch einfach weg.
Problematisch wird es, wenn die Funktion \(f\) nicht für alle reellen Zahlen definiert ist.
In der reellen Zahlenfolge können nämlich im Prinzip beliebige reelle Zahlen vorkommen
und der Funktionswert ist dann für bestimmte Folgenglieder möglicherweise gar nicht
definiert.
Wir könnten nun einfach verlangen, dass als Definitionsbereich von \(^*f\)
nur solche Zahlenfolgen erlaubt sind,
bei denen alle Folgenglieder im Definitionsbereich von \(f\) liegen.
Damit würden wir jedoch über das Ziel hinausschießen, denn normalerweise sind gar nicht
alle Folgenglieder wichtig, sondern nur diejenigen, deren Positionen durch eine
dominante Indexmenge vorgegeben werden.
Bezeichnen wir den Definitionsbereich von \(f\) mit \(D\).
Analog zur Gleich-Indexmenge von oben definieren wir die \(D\)-Indexmenge von \(x\)
als die Menge aller Indices, an denen die Folgenglieder von \(x\) in \(D\) liegen.
An diesen Stellen der Folge können wir problemlos den Funktionswert bilden.
Wir verlangen nun, dass dies bei der Mehrheit der Folgenglieder
möglich sein soll, d.h. wir fordern, dass die \(D\)-Indexmenge von \(x\) dominant ist
(also im gewählten freien Ultrafilter liegt).
Die Menge der Folgen, deren \(D\)-Indexmenge dominant ist, bezeichnen wir mit \(^*D\)
(dabei können wir gleiche Folgen zuvor auch gerne zu Äquivalenzklassen zusammenfassen).
In \(^*D\) liegen also alle Folgen, bei denen die Mehrheit der Folgenglieder
in \(D\) liegen.
Auf diesen Folgen können wir nun \(f\) leicht definieren, indem wir
an den Positionen der \(D\)-Indexmenge den Funktionswert hinschreiben
und an die restlichen Positionen einfach eine Null setzen, denn diese Positionen
werden nicht relevant sein.
Als Beispiel schauen wir uns die Wurzelfunktion \( \sqrt{()} \) an,
die nur für positive reelle Zahlen einschließlich Null definiert ist.
Zum Definitionsbereich \(^*D\) von \( ^*\sqrt{()} \) gehören dann alle Folgen, bei denen
die Mehrheit der Folgenglieder größer-gleich Null ist.
Die Indexmenge, die diese Positionen kennzeichnet, muss dominant sein, also
zum freien Ultrafilter gehören.
Beispielsweise gehört die Folge
\[
a = ( -1, 0, 1, 2, 3, ... )
\]
zu \(^*D\), denn nur die erste Position tanzt aus der Reihe.
Die Folge ist sogar eine unendlich große Zahl.
Die Wurzelfunktion für \(a\) wäre dann so definiert:
\[
^*\sqrt{a} := (0, \sqrt{0}, \sqrt{1}, \sqrt{2}, \sqrt{3}, ... )
\]
d.h. an die irrelevante erste Position haben wir einfach eine Null gesetzt.
Ausgehend von irgendeiner Teilmenge \(D\) der reellen Zahlen haben wir oben die
Teilmenge \(^*D\) der hyperreellen Zahlen gebildet:
Für Folgen aus \(^*D\) muss die Mehrheit der Folgenglieder in \(D\) liegen.
Anders gesagt: Die \(D\)-Indexmenge der Folgen muss im freien Ultrafilter liegen.
Auf diese Weise können wir z.B. ausgehend von den natürlichen Zahlen \( \mathbb{N} \)
die hypernatürlichen Zahlen \( ^*\mathbb{N} \) bilden – das sind die Folgen, bei denen
die Mehrheit der Folgenglieder natürliche Zahlen sind.
Analog geht es mit den rationalen Zahlen.
Was geschieht, wenn \(D\) eine endliche Teilmenge der reellen Zahlen ist?
Schauen wir uns ein Beispiel an: \( D = \{0\} \).
Dann besteht \(^*D\) aus allen Folgen, bei denen die Mehrheit der Folgenglieder
gleich Null ist. Nach unserer Definition der Gleichheit von Folgen
ist dann jede Folge aus \(^*D\) gleich der konstanten Folge \( 0 = (0, 0, 0, ... ) \),
d.h. \(^*D\) ist isomorph (gleichwertig) zur Menge \(D\). Man könnte in gewissem
Sinn sogar sagen, \(^*D\) und \(D\) sind gleich,
wenn wir die Folge \(0\) mit der reellen Zahl \(0\) gleichsetzen – so
hatten wir ja die reellen Zahlen innerhalb der hyperreellen Zahlen dargestellt.
Analog ist es bei allen endlichen Mengen, d.h. für endliche Mengen ist \(^*D = D\).
Wie sieht es aus, wenn \(D\) eine unendliche Teilmengen der reellen Zahlen ist?
Dann können wir eine unendliche Folge \(x\) bilden, die als Folgenglieder ausschließlich Elemente
von \(D\) enthält und bei der alle Folgenglieder verschieden sind.
Wäre \(D\) endlich, dann ginge das nicht.
Die Folge \(x\) liegt in \(^*D\), denn sogar jedes Folgenglied gehört zu \(D\).
Im Rahmen der hyperreellen Zahlen würde man die Elemente aus \(D\) durch konstante Folgen
\( y = (y, y, y, ... ) \) mit \(y \in D\) darstellen sowie alle dazu gleichen Folgen
hinzunehmen. Die Folge \(x\) von oben stimmt nun mit jeder dieser konstanten Folgen
höchstens an einer einzigen Position überein, kann also nicht gleich \(y\) sein.
Also haben wir eine Folge \(x\) gefunden, die nicht in \(D\) ist.
Die Menge \(^*D\) ist also größer als die Menge \(D\). Man kann allgemein zeigen:
Eine Teilmenge \(D\) der reellen Zahlen ist genau dann unendlich,
wenn \(^*D\) größer als \(D\) ist (also Elemente enthält, die keine reellen Zahlen sind).
Wir merken, wie wir immer mehr Begriffe aus den reellen Zahlen in die
hyperreellen Zahlen übertragen. Aus reellen Zahlen werden hyperreelle Zahlen,
aus Teilmengen \(D\) werden hyperreelle Teilmengen \(^*D\) und aus Funktionen \(f\) werden
hyperreelle Funktionen \(^*f\).
Die Versuchung liegt nahe, einen allgemeinen \(^*\)-Operator zu definieren,
der ganz allgemein die Standardobjekte der normalen Analysis in die
hyperreellen Zahlen überträgt. Das wollen wir uns jetzt genauer ansehen.
Das Transferprinzip
Aufbauend auf den hyperreellen Zahlen wollen wir eine Mathematik aufbauen,
in der alles, was es über die reellen Zahlen zu sagen gibt, enthalten ist.
Das bedeutet, dass jede wahre wohlgeformte Aussage über die reellen Zahlen
in eine entsprechende wahre Aussage über die hyperreellen Zahlen umgewandelt werden kann.
Auch der umgekehrten Weg soll gelten, so dass wir
ausgehend von den hyperreellen Zahlen
Aussagen über die reellen Zahlen gewinnen können.
Dass Beides möglich ist, sichert das sogenannte
Transferprinzip.
Transferprinzip:
Eine wohlgeformte Aussage \( \phi \) aus der Standardanalysis ist genau dann wahr,
wenn die in die Nichtstandardanalysis übertragene Aussage \( ^*\phi \) wahr ist.
Dies ist ein sehr mächtiges Resultat der mathematischen Logik und basiert auf
dem sogenannten Satz von Los (Los's theorem)
(siehe Wikipedia: Ultraprodukt).
Im Beweis des Satzes von Los braucht man letztlich genau das, was wir oben
über Ultrafilter und Größenvergleiche hyperreeller Zahlen gelernt haben.
Es würde jedoch zu weit führen, auf den langen Beweis an dieser Stelle näher einzugehen.
Im Transferprinzip ist von wohlgeformten Aussagen aus der Standardanalysis die Rede.
Das müssten wir eigentlich genauer definieren, aber intuitiv ist klar, dass es um
Variablen aus dem Bereich der reellen Zahlen und um Funktionen geht.
Um über den Wahrheitswert von solchen Aussagen reden zu können, brauchen wir
ein Modell im Rahmen der Mengenlehre (siehe Kapitel 4.4).
Die Modelldömäne \(D_J\) (also der Wertebereich der Variablen der Sprache)
ist bei der Standardanalysis die Menge der reellen Zahlen.
Damit ist klar, dass in den Aussagen der Standardanalysis
nur über Teilmengen der reellen Zahlen quantifiziert werden darf,
aber nicht über Teilmengen der Potenzmenge der reellen Zahlen
(das ist die Menge aller Teilmengen der reellen Zahlen).
Man darf also beispielsweise sagen "für alle positiven reellen Zahlen gilt ... ",
man darf aber nicht sagen "für alle Teilmengen der reellen Zahlen gilt ... ".
Analog ist es bei wohlgeformten Aussagen aus der Nichtstandardanalysis.
Im Grunde ist hiermit ein Nicht-Standardmodell der formalen Sprache der Analysis gemeint,
d.h. die Modelldömäne \(D_J\) (also der Wertebereich der Variablen der Sprache)
ist jetzt die Menge der hyperreellen Zahlen.
Wie man eine Teilmenge \(D\) der reellen Zahlen in eine Teilmenge \(^*D\) der hyperreellen Zahlen
umwandelt, haben wir oben ja bereits gesehen.
Auch für Funktionen kennen wir
die Übertragung in die Nichtstandardanalysis schon, und ähnlich geht es auch für andere
Objekte der Analysis. So entsteht aus einer Aussage \( \phi \) letztlich eine Aussage \( ^*\phi \).
Zu einer Aussage \( \phi \) der Form "für alle reellen Zahlen aus \(D\) gilt ... "
würde also eine Aussage \( ^*\phi \) mit der Form
"für alle hyperreellen Zahlen aus \(^*D\) gilt ... " gehören.
Für Teilmengen der Potenzmenge der reellen Zahlen (also für eine Menge aus Teilmengen
der reellen Zahlen) haben wir dagegen keine solche Übertragung in die hyperreellen Zahlen,
und das aus gutem Grund:
Aus Sicht der reellen Zahlen wäre "für alle Teilmengen der reellen Zahlen gilt ... "
eine Aussage zweiter Ordnung über alle Eigenschaften
der reellen Zahlen, denn eine Teilmenge der reellen Zahlen kann man als eine Ansammlung
reeller Zahlen mit derselben Eigenschaft ansehen.
Reelle und hyperreelle Zahlen
müssen sich aber in ihren Eigenschaften irgendwo unterscheiden, sonst wären sie identisch.
Gewisse Eigenschaften
(Teilmengen) der reellen Zahlen können deshalb nicht in entsprechende Eigenschaften (Teilmengen)
der hyperreellen Zahlen übergehen – ein Beispiel kommt gleich.
Anmerkung: Aus Sicht der Mengenlehre wäre eine Aussage der Form
für alle Teilmengen der reellen Zahlen gilt ... von erster Ordnung,
da ja über Mengen quantifiziert wird. Die Mengenlehre bietet über die Potenzmengen
gleichsam die Möglichkeit, Aussagen zweiter Ordnung über die Eigenschaften von Objekten
in Aussagen erster Ordnung (dann über Teilmengen von Potenzmengen) umzuwandeln.
Auf diese Weise ist es in Kapitel 4.2 gelungen, das Induktionsaxiom
als Aussage erster Ordnung im Rahmen der Mengenlehre zu formulieren, obwohl es in dieser Form
eine Aussage über Eigenschaften (Teilmengen) der natürlichen Zahlen ist.
Dies ist einer der Hauptgründe für die große Ausdruckskraft der Mengenlehre!
Hier ein konkretes Beispiel für eine Aussage, für die das Transferprinzip nicht gilt:
Dedekind-Vollständigkeit
der reellen Zahlen:
Jede nichtleere Teilmenge \(A\) der reellen Zahlen,
die eine reelle obere Schranke
besitzt (d.h. es gibt eine reelle Zahl \(b\), so dass alle Elemente \(x \in A\)
kleiner-gleich dieser oberen Schranke \(b\) sind), hat zugleich eine
\(kleinste\) obere reelle Schranke (d.h. es gibt keine andere obere Schranke von \(A\), die kleiner
als die kleinste obere Schranke von \(A\) ist – deshalb heißt sie ja auch kleinste ...).
Man nennt die kleinste obere Schranke
auch Supremum. Das Supremum muss dabei nicht zu \(A\) gehören.
Das ist eine Aussage über alle Teilmengen der reellen Zahlen,
ist also aus Sicht der reellen Zahlen von zweiter Ordnung.
Als Beispiel können wir für \(A\) alle reellen Zahlen nehmen, deren Quadrat kleiner als 2 ist:
\[
A = \{x \in \mathbb{R} , \, x^2 < 2 \}
\]
Diese Menge besitzt eine obere Schranke, z.B. die Zahl 1,5 , denn jedes \(x \in A\)
ist kleiner als 1,5 . Die Menge muss deshalb auch eine kleinste obere Schranke besitzen, nämlich
die reelle Zahl \( \sqrt{2} = 1,4142... \) , die aber selbst nicht zu \(A\) gehört.
Die Dedekind-Vollständigkeit gilt nicht innerhalb der Menge
\( \mathbb{Q} \) der rationalen Zahlen (Brüche).
Die Aussage "Jede nichtleere Teilmenge \(A\) der rationalen Zahlen,
die eine rationale obere Schranke
besitzt, hat zugleich eine kleinste obere rationale Schranke"
ist falsch, wie das obige Beispiel sofort zeigt:
Die Menge \(A\) der rationalen Zahlen, deren Quadrat kleiner als 2 ist,
hat zwar eine rationale obere Schranke (z.B. 1,5), aber keine kleinste obere rationale Schranke.
Man kann sich nämlich von oben mit rationalen Zahlen beliebig weit
an \( \sqrt{2} \) annähern, aber \( \sqrt{2} \) ist selbst keine rationale Zahl.
Zu jeder rationalen oberen Schranke von \(A\) findet man also einen Bruch, der
noch näher an \( \sqrt{2} \) dran ist und demnach eine noch kleinere rationale obere Schranke darstellt.
Tatsächlich kann man mit der Dedekind-Vollständigkeit
die reellen Zahlen aus den rationalen Zahlen sogar konstruieren,
indem man die kleinsten oberen Schranken aller Teilmengen einfach
mit hinzunimmt. Insofern wird klar, dass die Dedekind-Vollständigkeit keine Aussage
der Analysis ist, sondern zur mengentheoretischen Konstruktion der Modelldomäne
dazugehört. Sie ist eine Aussage über die gewählte Modellmenge, die als Wertebereich für die Variablen der
Analysis in Frage kommt.
Die Dedekind-Vollständigkeit gilt nicht innerhalb der Menge \(^*R\) der hyperreellen Zahlen,
d.h. das Transferprinzip gilt für die Dedekind-Vollständigkeit nicht.
Die Existenz infinitesimaler Zahlen zerstört die Dedekind-Vollständigkeit.
Nehmen wir als Beispiel alle hyperreellen Zahlen, die kleiner als alle positiven reellen Zahlen sind.
Würden wir nur reelle Zahlen zulassen, so wäre dies die Menge der negativen reellen Zahlen
einschließlich Null. Die kleinste obere Schranke wäre also Null. Bei den hyperreellen Zahlen
ist das aber schwieriger: Auch die infinitesimale Zahl \(dx\) ist kleiner als jede positive
reelle Zahl, aber größer als Null – also ist Null keine obere Schranke mehr.
Als obere Schranke müsste man also die kleinste positive reelle Zahl nehmen, denn
nur dann sind auch die infinitesimalen Zahlen kleiner als diese Schranke.
Dummerweise gibt es aber keine kleinste positive reelle Zahl, also gibt es auch keine kleinste obere
Schranke.
Hier ein Beispiel für eine Aussage aus dem Bereich der hyperreellen Zahlen,
zu der es keine passende Aussage in den reellen Zahlen gibt:
"Es gibt hyperreelle Zahlen, die größer sind als jede reelle Zahl."
Auch dies ist keine Aussage der Analysis, sondern
eine mengentheoretische Aussage über die Modellmenge der hyperreellen Zahlen.
Für diese Ausage gilt
das Transferprinzip nicht, denn als Variablenbereiche werden
einmal die reellen und einmal die hyperreellen Zahlen verwendet.
Es ist tatsächlich so, dass man mit dem Transferprinzip die hyperreellen Zahlen und
die Nichtstandard-Analysis scheinbar fast ohne unendliche Zahlenfolgen und freie Ultrafilter
aufbauen kann. Diese Herangehensweise findet man oft in Büchern, aber sie hat den Nachteil,
recht abstrakt zu sein. Wenn man dagegen wie wir mit unendlichen Zahlenfolgen startet,
so hat man wenigstens auf dem Weg etwas Konkretes in der Hand, während man unbekanntes
Neuland betritt. Außerdem sind die freien Ultrafilter natürlich in jedem Fall da,
sie verstecken sich nur hinter dem Satz von Los.
Wenn man aber den Umgang mit hyperreellen Zahlen schon etwas gewohnt sind,
dann gibt einem das Transferprinzip die Möglichkeit, die unendlichen Zahlenfolgen
teilweise zu vergessen und sie analog zu reellen Zahlen zu behandeln.
Auch bei reellen Zahlen denken wir ja nicht ständig an Cauchyfolgen.
Vom Nutzen der Nichtstandard-Analysis
Von hier an geht es natürlich erst richtig los.
Alle Begriffe der Standardanalysis müssen Schritt für Schritt in die
Nichtstandardanalysis übertragen werden. Dies gelingt zum Teil mit
intuitiv sehr gut verständlichen Formulierungen. Hier einige Beispiele:
Grenzwert einer Funktion:
\(L\) heißt Grenzwert einer Funktion \(f\) an der Stelle \(x\), wenn
\( L \simeq f(x+dx) \) ist (mit infinitesimalem \(dx\) ungleich Null).
Stetigkeit einer Funktion:
Eine Funktion \(f\) ist stetig an der reellen Stelle \(x\), wenn
\( f(x+dx) \simeq f(x) \) ist.
Ableitung einer Funktion (Differenzierbarkeit):
Die Ableitung \( f'(x) \) einer Funktion \(f\) an der reellen Stelle \(x\) ist gegeben durch
\[
f'(x)
= \mathrm{st} \left( \frac{df(x)}{dx} \right) = \]
\[
= \mathrm{st} \left( \frac{f(x+dx) - f(x)}{dx} \right)
\]
Als Physiker bin ich natürlich begeistert, dass
diese in der Physik gängigen Schreibweisen nun auch streng mathematisch
rehabilitiert sind.
Auch die in der Physik bekannte Ableitung der Produktregel darf man nun endlich hinschreiben,
ohne sich dafür entschuldigen zu müssen.
Dabei wird verwendet, dass \( df(x) := f(x+dx) - f(x) \)
auch als \( f(x+dx) = f(x) + df(x) \) umgestellt
werden kann (analog für \(g\)), dass der Standardteil einer Summe gleich der Summe der
Standardteile ist und dass der Standardteil einer infinitesimalen Zahl gleich Null ist
(das Argument \( (x) \) lassen wir zur Vereinfachung der Schreibweise teilweise weg,
schreiben also beispielsweise \( df \) statt \( df(x) \) ):
Das ist doch sehr elegant: Im Grunde hat man nur den Zähler ausmultipliziert und den doppelt-infinitesimalen
Teil weggelassen. Dies dürfte der Intuition von Newton und Leibniz sehr nahe gekommen sein!
Offenbar lassen sich in der Nichtstandardanalysis viele Definitionen
und Beweise intuitiver schreiben als mit dem umständlichen \(\epsilon - \delta\) -Formalismus.
Das Transferprinzip garantiert uns, dass zu jeder wahren Aussage \(^*\phi\)
aus der Nichtstandardanalysis auch das Gegenstück \(\phi\) aus der Analysis wahr ist.
Man kann also elegante Beweise aus der Nichtstandardanalysis dazu verwenden,
um zugleich auch die entsprechenden Aussagen der Standardanalysis zu beweisen.
Das haben wir mit der Produktregel oben gerade getan.
Kritiker wenden oft ein, dass die Objekte der Nichtstandardanalysis nicht
konstruiert werden können – man kann die Äquivalenzklassen nicht explizit hinschreiben.
Dies liegt am nicht-konstruktiven Charakter des Auswahlaxioms, das man für die
Existenz der Ultrafilter braucht. Hyperreelle Zahlen werden daher manchmal als
Fiktion angesehen, analog zu nicht-messbaren Punktmengen, die man manchmal auch
als mathematische Monster bezeichnet. Man nimmt sie in Kauf, da man das nützliche
Auswahlaxiom braucht.
Vermutlich hilft hier nur ein pragmatischer Ansatz:
Die Existenz hyperreeller Zahlen ist mathematisch denkbar, d.h. wir dürfen ihre
Existenz in dem Sinn annehmen, dass dies keine Widersprüche erzeugt.
Mathematische Welten müssen nicht perfekt oder konstruierbar sein.
Es reicht, dass sie denkbar sind, und besonders gut ist es, wenn sie auch noch
Nutzen stiften. Das ist hier sicher der Fall, denn
die Nichtstandardanalysis stellt ein mächtiges und elegantes Werkzeug zur Beweisführung
zur Verfügung.
Wer weiß: Vielleicht wird eines Tages die Nichtstandardanalysis sogar die
bevorzugte Formulierung werden, während die heute gebräuchliche \(\epsilon - \delta\) -Formalismus
in den Hintergrund tritt. Die Mode ändert sich mit der Zeit, auch in der Mathematik.
Schon Kurt Gödel hat in der Nichtstandardanalysis die Analysis der Zukunft gesehen.
Mal schauen, ob er Recht hat.
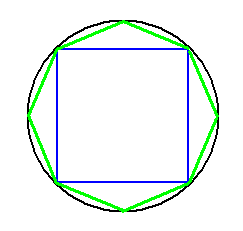
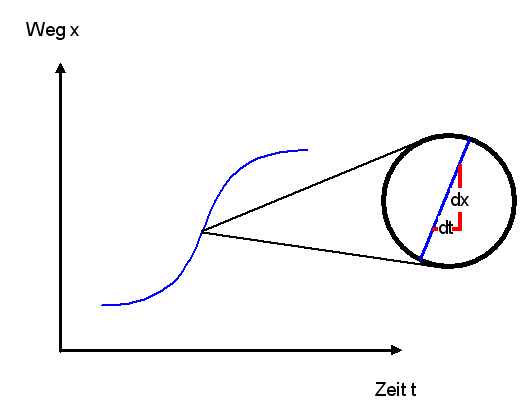


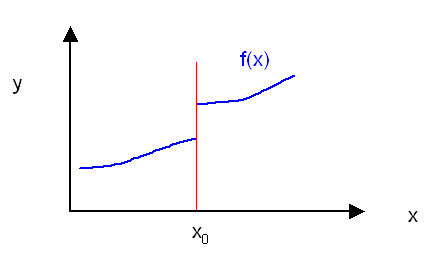
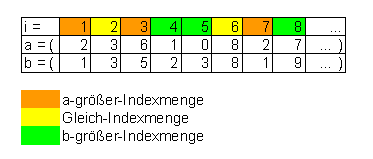
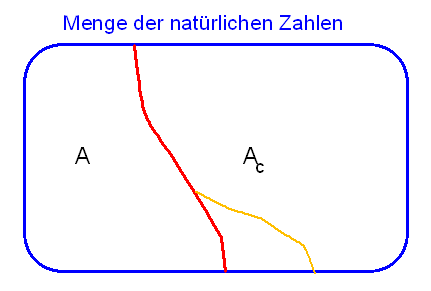
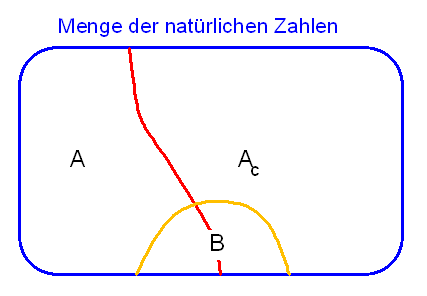
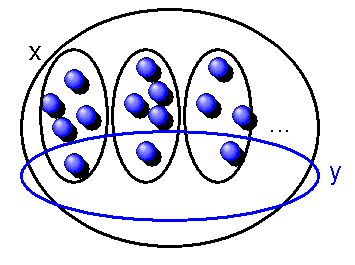
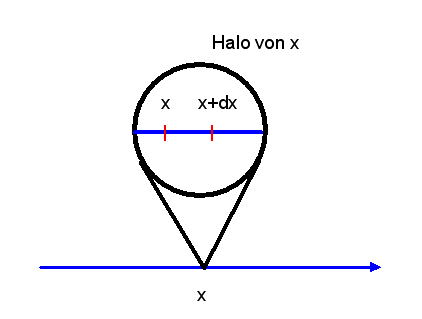
{kind=link}
{kind=link}